2025 4月全球机器学习技术大会-上海站

课时介绍
微软亚洲研究院高级研究员,Logic-RL贡献者
我们探讨基于规则的强化学习(RL)在大规模推理模型中的潜力。受DeepSeek-R1成功的启发,我们通过合成逻辑谜题作为训练数据,分析推理动态。这些逻辑谜题因其可控的复杂性和简单的答案验证过程而成为理想的训练数据。本研究提出了几项关键技术贡献,包括强调思维和回答过程的系统提示、惩罚捷径输出的严格格式奖励函数,以及实现稳定收敛的简单训练方案。我们的7B模型在训练仅5,000个逻辑问题后,展示了在挑战性数学基准测试AIME和AMC上的泛化能力。
课程介绍
自1936年阿兰· 图灵提出「图灵机」以及机器具备「思维」的可能性以来,以机器学习为代表的人工智能经过飞速发展,深刻地改变着我们的世界。CSDN & Boolan 秉承“全球专家,卓越智慧”的宗旨,特邀近50位技术领袖和行业应用专家,与1000+来自电商、金融、汽车、智能制造、通信、工业互联网、医疗、教育等众多行业的精英参会听众,共同探讨人工智能领域的前沿发展和行业最佳实践。
推荐课程

信息系统项目管理师自考笔记
李明 · 1008人在学
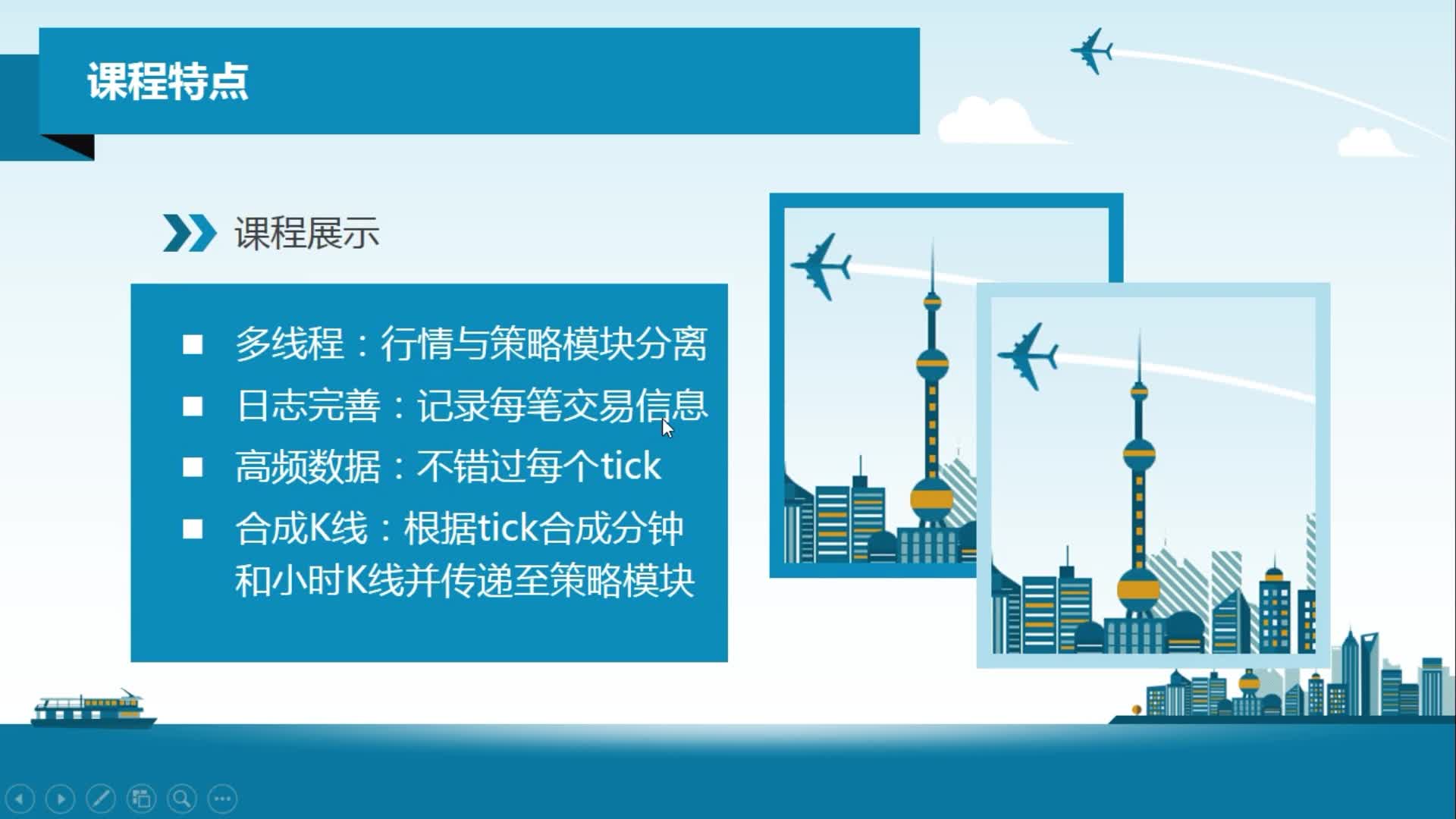
python从0到1:期货量化交易系统(CTP实战,高频及合成K线数据
王先生 · 23127人在学

手把手搭建Java超市管理系统【附源码】(毕设)
汤小洋 · 4330人在学
Java毕设springboot外卖点餐系统 毕业设计毕设源码 使用教
黄菊华 · 856人在学
基于SSM酒店管理系统(毕设)
小尼老师 · 922人在学
java项目实战之购物商城(java毕业设计)
Long · 5223人在学

手把手搭建Java求职招聘系统【附源码】(毕设)
汤小洋 · 1546人在学
Python Django 深度学习 小程序
钟翔 · 2446人在学

城管局门前三包管理系统+微信小程序(vue+springboot)
赖国荣 · 727人在学
Vue+Uni-app(uniapp)入门与实战+赠送仿美团点餐小程序
李杰 · 4117人在学