学习Grad-CAM热力图可视化原理
掌握YOLOv5上的Grad-CAM热力图可视化方法
 分享
分享 

YOLOv5目标检测之Grad-CAM热力图可视化
你将收获
学习Grad-CAM热力图可视化原理
掌握YOLOv5上的Grad-CAM热力图可视化方法
适用人群
课程介绍
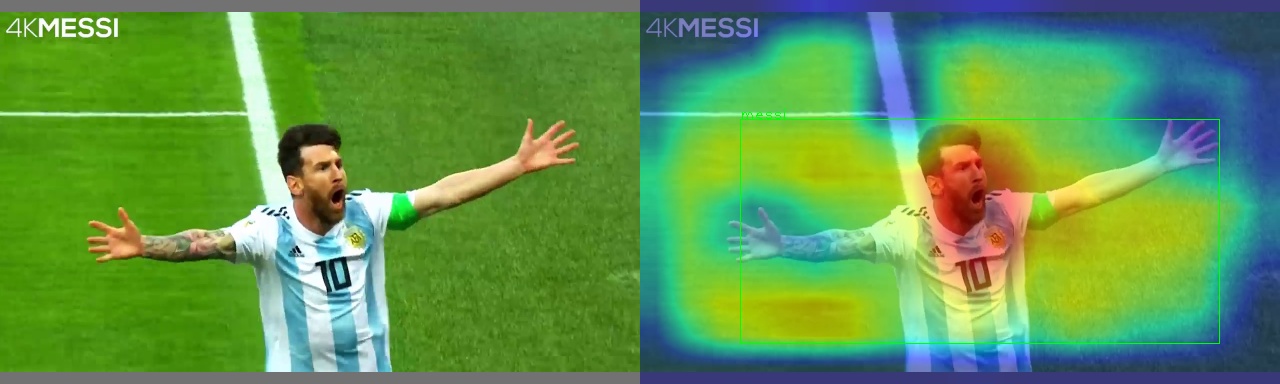
PyTorch版的YOLOv5是一个非常流行的基于深度学习的目标检测器。本课程使用Grad-CAM热力图可视化方法对YOLOv5进行热力图可视化,可直观展示图像中哪些区域对类别分类贡献程度大。
Grad-CAM是一种CNN(卷积神经网络)可解释性的经典方法,与CAM(类激活图)相比,不需要对模型进行改动就可以生成热力图(heatmap),非常方便和灵活。
本课程在YOLOv5 v6.1版本代码的基础上增加Grad-CAM热力图可视化方法,并演示针对自己的数据集训练和进行Grad-CAM热力图可视化过程,并讲解原代码针对Grad-CAM热力图可视化的修改部分。
本课程分为原理篇、实战篇、代码讲解篇。
· 原理篇包括:Grad-CAM热力图可视化原理。
· 实战篇包括:PyTorch环境安装、YOLOv5项目安装、准备自己的数据集、修改配置文件、训练自己的数据集、Grad-CAM热力图可视化。
· 代码讲解篇包括:针对Grad-CAM热力图可视化具体修改的代码讲解。

课程目录