
Hadoopp生态圈实战班
hadoophivehbasekafka大数据
 分享
分享 

Hadoopp生态圈实战班
Hadoop生态圈主要用来解决海量数据的存储和分析计算问题。是大数据开发工程师必备技术之一。
课程特点:
1、全程案例贯穿始终,几乎每个知识点都有配套的案例;
2、整个框架深入源码讲解;
3、优化措施全部来源于企业开发;
4、Hadoop生态圈相关企业真题全覆盖。
第一章 Hadoop、Zookeeper
第二章 数据仓库工具hive
第三章 HA
第四章 Flume
第五章 分布式数据库Hbase
第六章 批量数据迁移的工具Sqoop
第七章 批量工作流任务调度器Azkaban
第八章 任务调度框架Oozie
第九章 亚秒级查询工具Kylin
复制链接
扫一扫
CTO/CIO/技术副总裁/总工程师
张长志技术全才、擅长领域:区块链、大数据、Java等。10余年软件研发及企业培训经验,曾为多家大型企业提供企业内训如中石化,中国联通,中国移动等知名企业。拥有丰富的企业应用软件开发经验、深厚的软件架构设计理论基础及实践能力。项目开发历程:基于大数据技术推荐系统 ,医疗保险大数据分析与统计推断,H5跨平台APP,携程酒店APP,Go语言实现Storm和ZK类似框架。
张长志技术全才、擅长领域:区块链、大数据、Java等。10余年软件研发及企业培训经验,曾为多家大型企业提供企业内训如中石化,中国联通,中国移动等知名企业。拥有丰富的企业应用软件开发经验、深厚的软件架构设计理论基础及实践能力。项目开发历程:基于大数据技术推荐系统 ,医疗保险大数据分析与统计推断,H5跨平台APP,携程酒店APP,Go语言实现Storm和ZK类似框架。
包含课程
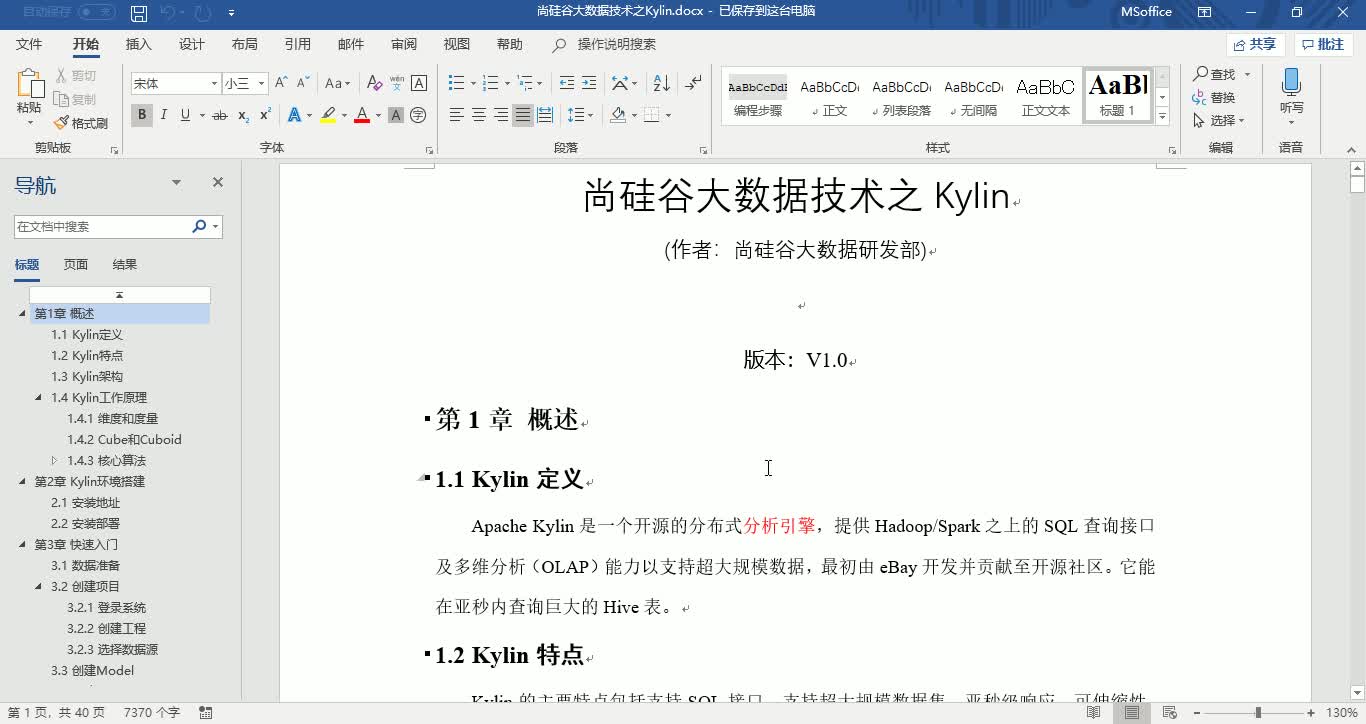
 401人 学习人数4.3分 课程评分超大数据集上的亚秒级查询工具Kylin教程Apache Kylin™是一个开源的分布式分析引擎,提供Hadoop/Spark之上的SQL查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由eBay Inc. 开发并贡献至开源社区。它能在亚秒内查询巨大的Hive表。 Apache Kylin™令使用者仅需三步,即可实现超大数据集上的亚秒级查询。 * 定义数据集上的一个星形或雪花形模型 * 在定义的数据表上构建cube * 使用标准SQL通过ODBC、JDBC或RESTFUL API进行查询,仅需亚秒级响应时间即可获得查询结果 Kylin提供与多种数据可视化工具的整合能力,如Tableau,PowerBI等,令用户可以使用BI工具对Hadoop数据进行分析。 本套教程主要对Kylin的基础理论的讲解,涉及到各种重要概念、原理和API的用法,并对Kylin优化进行深入剖析。通过理论和实际的紧密结合,可以使学员对Kylin有充分的认识和理解,对大数据技术有更全面的了解,为日后成长为架构师打下基础。云计算/大数据Hadoop大数据开源社区分布式
401人 学习人数4.3分 课程评分超大数据集上的亚秒级查询工具Kylin教程Apache Kylin™是一个开源的分布式分析引擎,提供Hadoop/Spark之上的SQL查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由eBay Inc. 开发并贡献至开源社区。它能在亚秒内查询巨大的Hive表。 Apache Kylin™令使用者仅需三步,即可实现超大数据集上的亚秒级查询。 * 定义数据集上的一个星形或雪花形模型 * 在定义的数据表上构建cube * 使用标准SQL通过ODBC、JDBC或RESTFUL API进行查询,仅需亚秒级响应时间即可获得查询结果 Kylin提供与多种数据可视化工具的整合能力,如Tableau,PowerBI等,令用户可以使用BI工具对Hadoop数据进行分析。 本套教程主要对Kylin的基础理论的讲解,涉及到各种重要概念、原理和API的用法,并对Kylin优化进行深入剖析。通过理论和实际的紧密结合,可以使学员对Kylin有充分的认识和理解,对大数据技术有更全面的了解,为日后成长为架构师打下基础。云计算/大数据Hadoop大数据开源社区分布式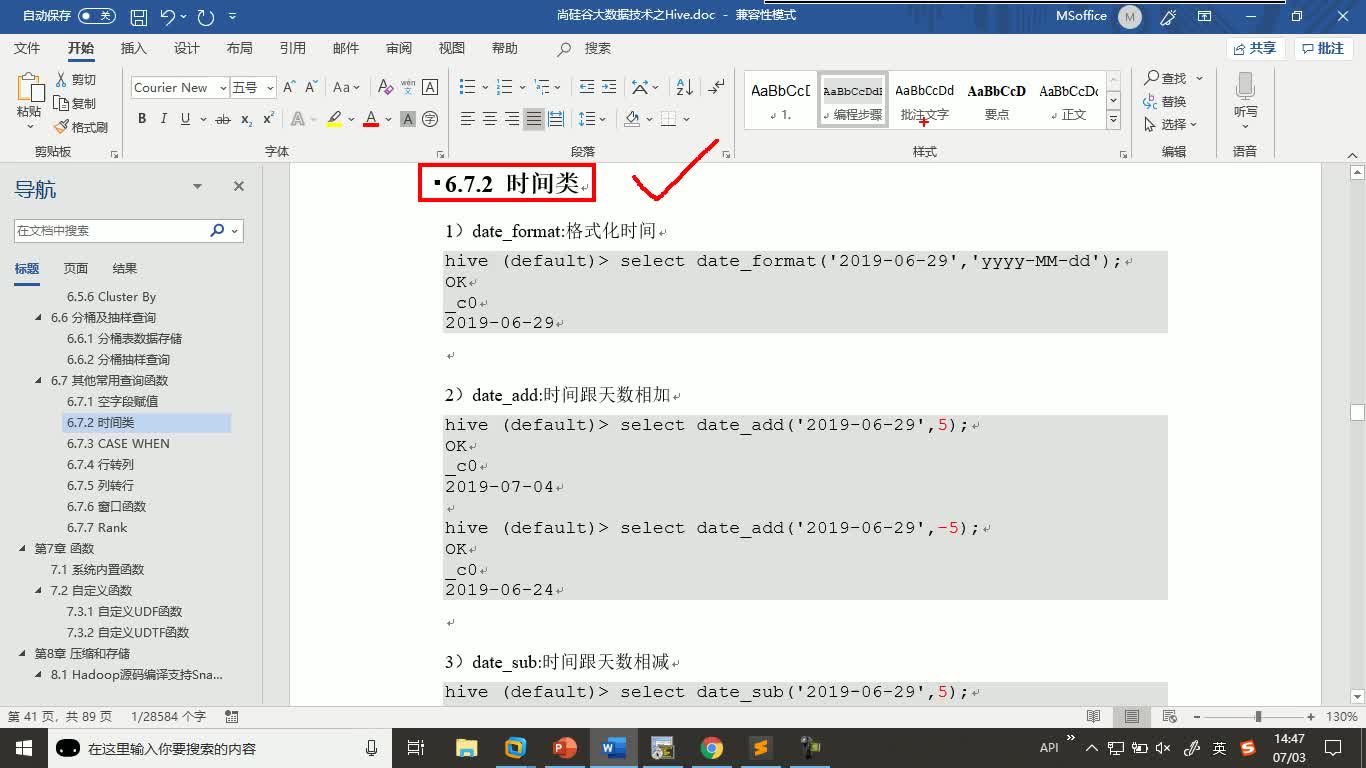 667人 学习人数4.3分 课程评分通俗易懂的Hive升级版教程(含配套资料)Hive是基于Hadoop的一个数据仓库工具,将繁琐的MapReduce程序变成了简单方便的SQL语句实现,深受广大软件开发工程师喜爱。Hive同时也是进入互联网行业的大数据开发工程师必备技术之一。在本课程中,你将学习到,Hive架构原理、安装配置、hiveserver2、数据类型、数据定义、数据操作、查询、自定义UDF函数、窗口函数、压缩和存储、企业级调优、以及结合影音项目需求,把整个Hive的核心知识点贯穿起来。更新:课件升级、添加自定义UDTF函数、企业常用函数以及更多企业面试真题详细讲解hive云计算/大数据大数据mapreduce函数
667人 学习人数4.3分 课程评分通俗易懂的Hive升级版教程(含配套资料)Hive是基于Hadoop的一个数据仓库工具,将繁琐的MapReduce程序变成了简单方便的SQL语句实现,深受广大软件开发工程师喜爱。Hive同时也是进入互联网行业的大数据开发工程师必备技术之一。在本课程中,你将学习到,Hive架构原理、安装配置、hiveserver2、数据类型、数据定义、数据操作、查询、自定义UDF函数、窗口函数、压缩和存储、企业级调优、以及结合影音项目需求,把整个Hive的核心知识点贯穿起来。更新:课件升级、添加自定义UDTF函数、企业常用函数以及更多企业面试真题详细讲解hive云计算/大数据大数据mapreduce函数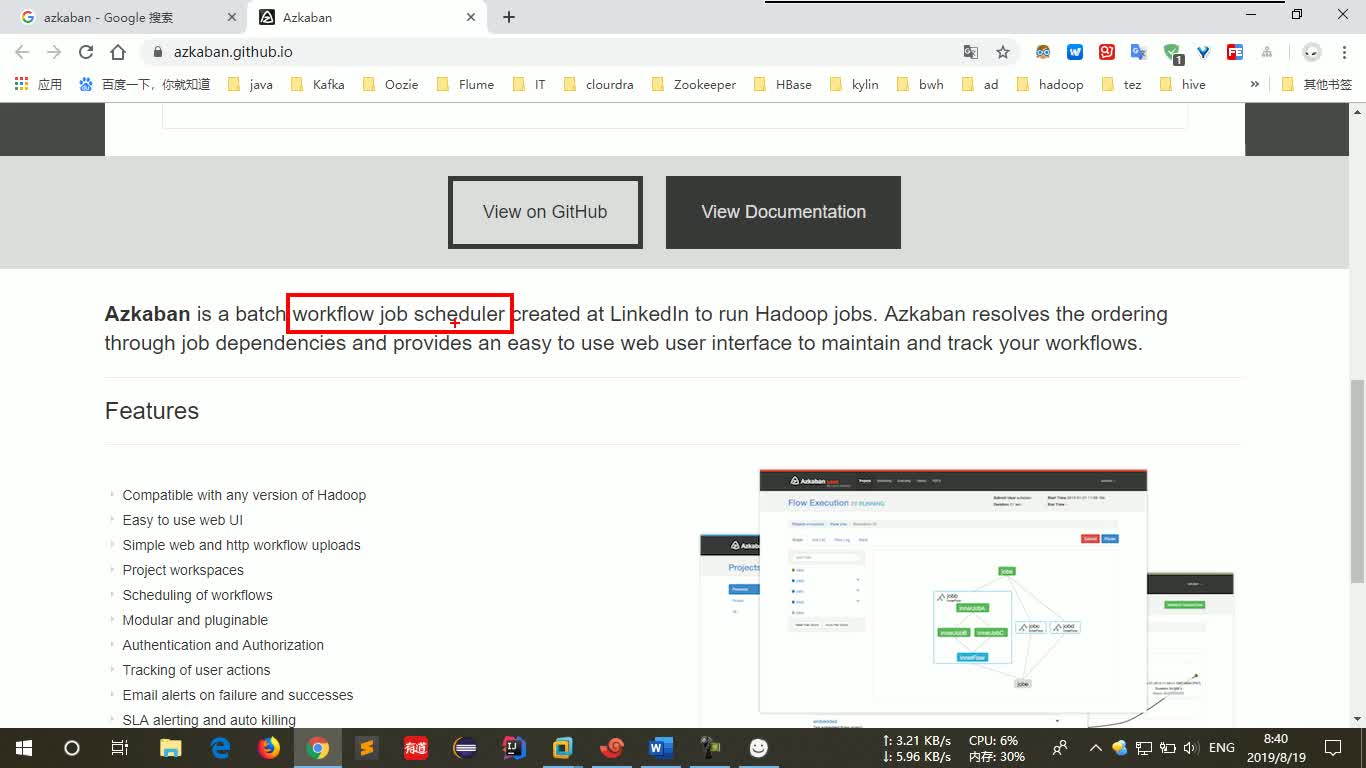 691人 学习人数4.3分 课程评分通俗易懂的Azkaban教程(含配套资料)Azkaban是一个Hadoop workflow定时调度工具,它解决了多个Hadoop任务单元之间的前后依赖关系。它提供了十分友好的用户界面,使用简单,容易上手。在本课程中,你将学到,Azkaban的安装部署,Azkaban基础架构,Azkaban定时调度工作流程(包含Shell、MapReduce、Hive等)、Azkaban邮箱通知。云计算/大数据大数据mapreducehadoopshell
691人 学习人数4.3分 课程评分通俗易懂的Azkaban教程(含配套资料)Azkaban是一个Hadoop workflow定时调度工具,它解决了多个Hadoop任务单元之间的前后依赖关系。它提供了十分友好的用户界面,使用简单,容易上手。在本课程中,你将学到,Azkaban的安装部署,Azkaban基础架构,Azkaban定时调度工作流程(包含Shell、MapReduce、Hive等)、Azkaban邮箱通知。云计算/大数据大数据mapreducehadoopshell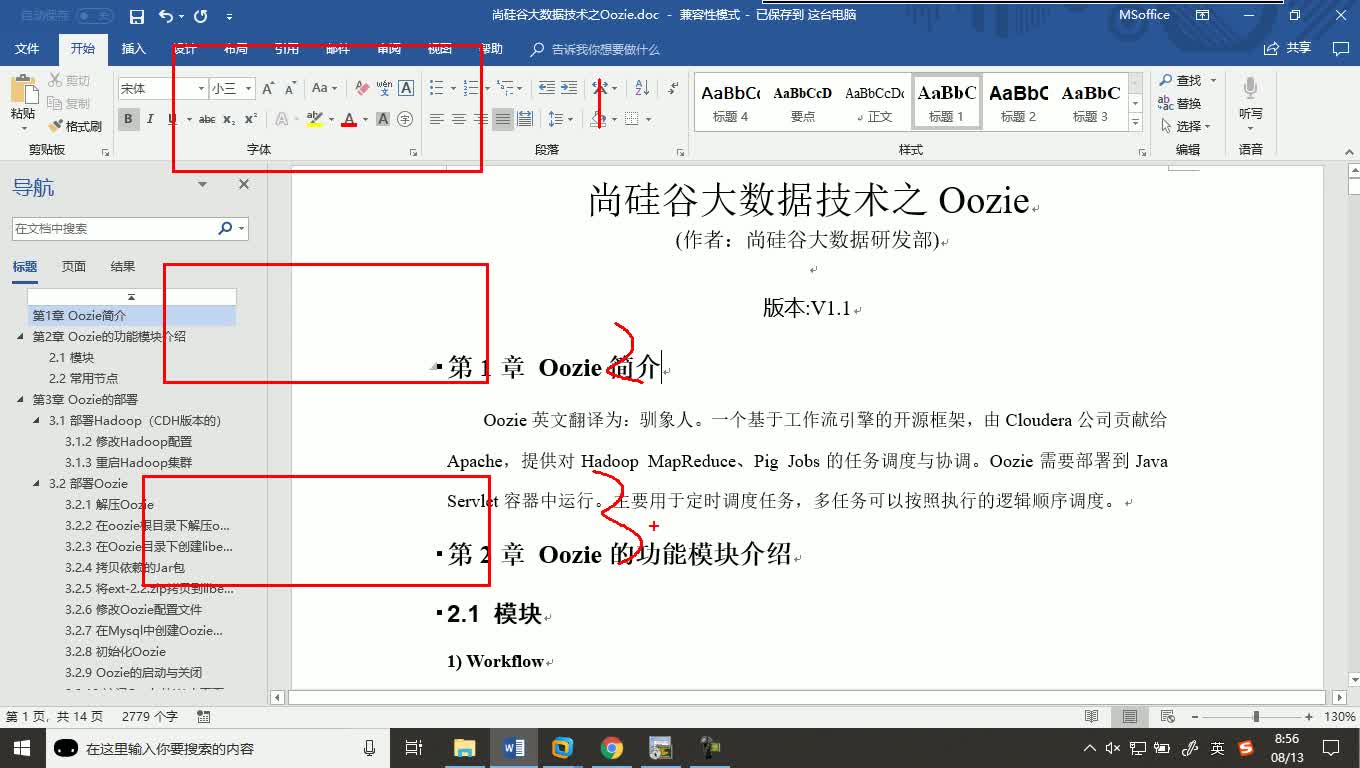 731人 学习人数4.3分 课程评分新版全面系统完整的Oozie教程本教程为官方授权出品教程 Oozie是大数据生态圈中一个基于工作流的任务调度工具,也是大数据工程师的一个常用工具。 在本课程中,你将学习到Oozie的原理、 安装配置、使用Oozie实现调度Shell脚本、 逻辑调度多个Shell脚本、 直接调度MapReduce任务以及定时逻辑调度多个任务等。云计算/大数据大数据mapreduceshell任务调度
731人 学习人数4.3分 课程评分新版全面系统完整的Oozie教程本教程为官方授权出品教程 Oozie是大数据生态圈中一个基于工作流的任务调度工具,也是大数据工程师的一个常用工具。 在本课程中,你将学习到Oozie的原理、 安装配置、使用Oozie实现调度Shell脚本、 逻辑调度多个Shell脚本、 直接调度MapReduce任务以及定时逻辑调度多个任务等。云计算/大数据大数据mapreduceshell任务调度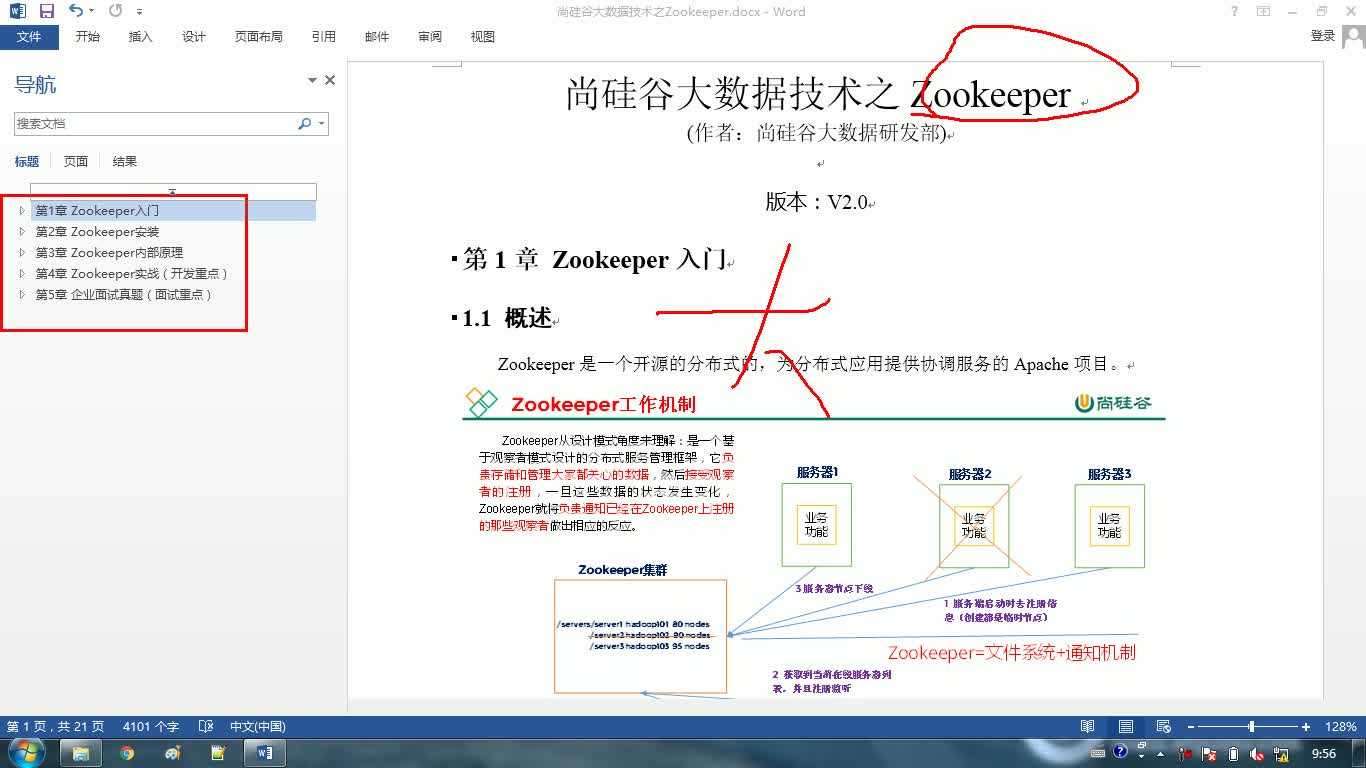 433人 学习人数4.3分 课程评分新版全面系统完整的Zookeeper视频教程Zookeeper主要应用于大数据开发中的,统一命名服务、统一配置管理、统一集群管理、服务器节点动态上下线、软负载均衡等场景。该框架相当于大数据框架中的润滑剂。是大数据大数据开发工程师必须会的框架之一。本套课程讲解了Zookeeper的集群安装、 选举机制、监听器原理、 写数据流程、Shell命令行操作、 客户端API操作、 服务器节点动态上下线综合案例,以及企业真实面试题。云计算/大数据大数据zookeeper视频shell
433人 学习人数4.3分 课程评分新版全面系统完整的Zookeeper视频教程Zookeeper主要应用于大数据开发中的,统一命名服务、统一配置管理、统一集群管理、服务器节点动态上下线、软负载均衡等场景。该框架相当于大数据框架中的润滑剂。是大数据大数据开发工程师必须会的框架之一。本套课程讲解了Zookeeper的集群安装、 选举机制、监听器原理、 写数据流程、Shell命令行操作、 客户端API操作、 服务器节点动态上下线综合案例,以及企业真实面试题。云计算/大数据大数据zookeeper视频shell 1053人 学习人数4.4分 课程评分新版全面系统完整的Hbase视频教程本教程为授权出品作品 HBase是一个基于HDFS的分布式、面向列的开源数据库,是一个结构化数据的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。是每一个大数据都应该掌握的基本框架。在本课程中,主要讲述了HBase详细的架构原理及特点、HBase内部各个角色的详细介绍、安装配置、HBase的Shell操作、新旧版本的读写数据详细流程、HBase的API操作、使用MapReduce以及Hive对HBase数据分析、Rowkey设计、预分区设计、调优策略以及结合谷粒微博项目将核心知识点再次梳理,更熟练的运用HBase。大数据视频hbase云计算/大数据mapreduce
1053人 学习人数4.4分 课程评分新版全面系统完整的Hbase视频教程本教程为授权出品作品 HBase是一个基于HDFS的分布式、面向列的开源数据库,是一个结构化数据的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。是每一个大数据都应该掌握的基本框架。在本课程中,主要讲述了HBase详细的架构原理及特点、HBase内部各个角色的详细介绍、安装配置、HBase的Shell操作、新旧版本的读写数据详细流程、HBase的API操作、使用MapReduce以及Hive对HBase数据分析、Rowkey设计、预分区设计、调优策略以及结合谷粒微博项目将核心知识点再次梳理,更熟练的运用HBase。大数据视频hbase云计算/大数据mapreduce 597人 学习人数4.0分 课程评分新版全面系统完整的Sqoop教程本教程为联合出品 Sqoop是大数据生态圈中一个数据传输工具,也是大数据工程师的一个常用工具。在本课程中,你将学习到,Sqoop的原理、安装配置、使用Oozie实现数据在Mysql与HDFS(Hive、HBase)等框架之间的互导。大数据视频技术云计算/大数据Hadoop
597人 学习人数4.0分 课程评分新版全面系统完整的Sqoop教程本教程为联合出品 Sqoop是大数据生态圈中一个数据传输工具,也是大数据工程师的一个常用工具。在本课程中,你将学习到,Sqoop的原理、安装配置、使用Oozie实现数据在Mysql与HDFS(Hive、HBase)等框架之间的互导。大数据视频技术云计算/大数据Hadoop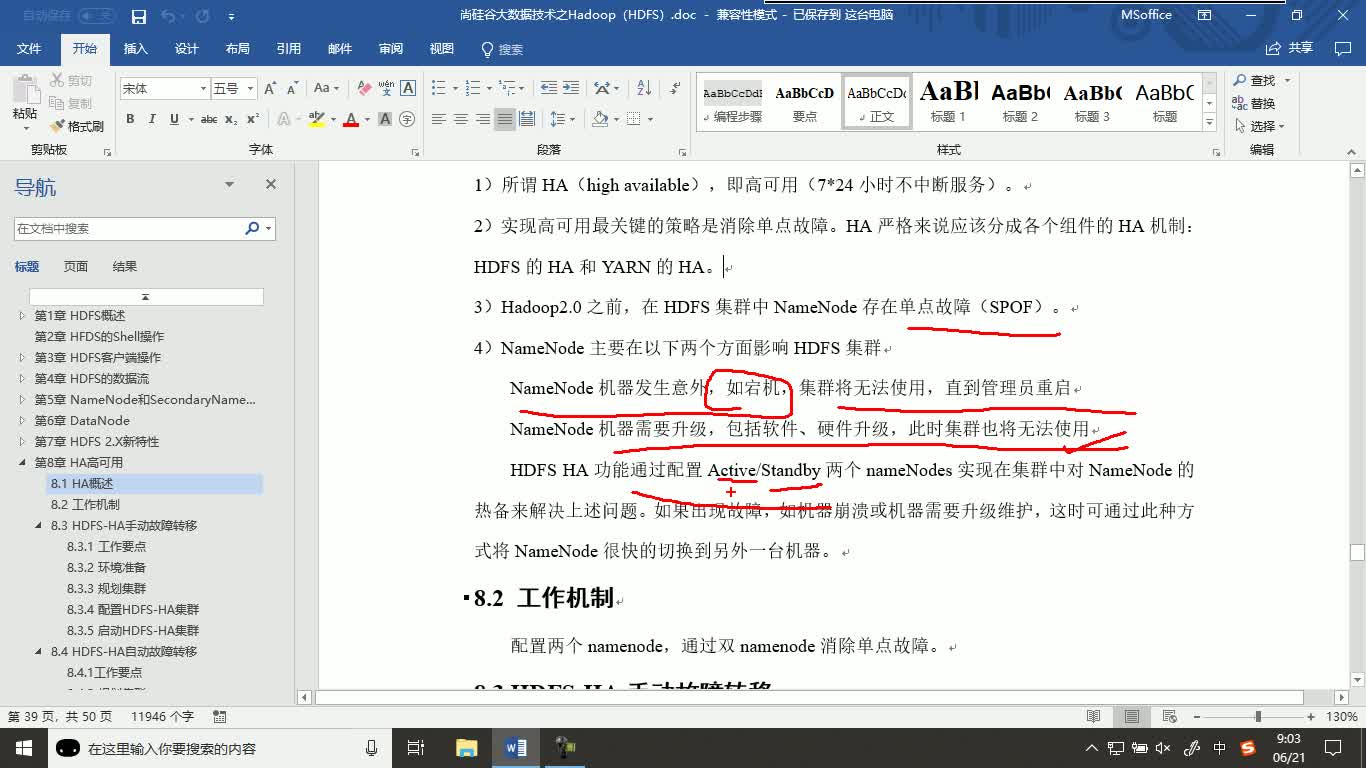 606人 学习人数4.0分 课程评分大数据技术之HA视频教程本教程由尚硅谷和张长志联合出品 HA(High Available)意为高可用,在本课程中主要是Hadoop的高可用,在实际开发环境中是必不可少的技术之一。 你将通过本课程学习到,Hadoop存在的单点故障问题,解决单点故障的方案,搭建手动故障转移的HDFS-HA集群,搭建基于Zookeeper的自动故障转移的HDFS-HA集群以及自动故障转移的Yarn-HA集群。 购买后资料问题请加老师QQ 2020363447大数据视频技术云计算/大数据Hadoop
606人 学习人数4.0分 课程评分大数据技术之HA视频教程本教程由尚硅谷和张长志联合出品 HA(High Available)意为高可用,在本课程中主要是Hadoop的高可用,在实际开发环境中是必不可少的技术之一。 你将通过本课程学习到,Hadoop存在的单点故障问题,解决单点故障的方案,搭建手动故障转移的HDFS-HA集群,搭建基于Zookeeper的自动故障转移的HDFS-HA集群以及自动故障转移的Yarn-HA集群。 购买后资料问题请加老师QQ 2020363447大数据视频技术云计算/大数据Hadoop 1121人 学习人数4.5分 课程评分全面系统完整的Flume教程Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统。Flume基于流式架构,灵活简单。是大数据大数据开发工程师必须会的框架之一。在本课程中,你将学习到,Flume架构原理、安装配置、拓扑结构、使用Flume搭建监控端口采集数据、监控本地(或HDFS)文件(或文件夹)采集数据、多数据源采集数据、多数据出口收集日志、Flume负载均衡以及对于Flume的监控Ganglia的运用。购买后资料问题请加老师QQ 2020363447云计算/大数据Hadoop大数据负载均衡工程师
1121人 学习人数4.5分 课程评分全面系统完整的Flume教程Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统。Flume基于流式架构,灵活简单。是大数据大数据开发工程师必须会的框架之一。在本课程中,你将学习到,Flume架构原理、安装配置、拓扑结构、使用Flume搭建监控端口采集数据、监控本地(或HDFS)文件(或文件夹)采集数据、多数据源采集数据、多数据出口收集日志、Flume负载均衡以及对于Flume的监控Ganglia的运用。购买后资料问题请加老师QQ 2020363447云计算/大数据Hadoop大数据负载均衡工程师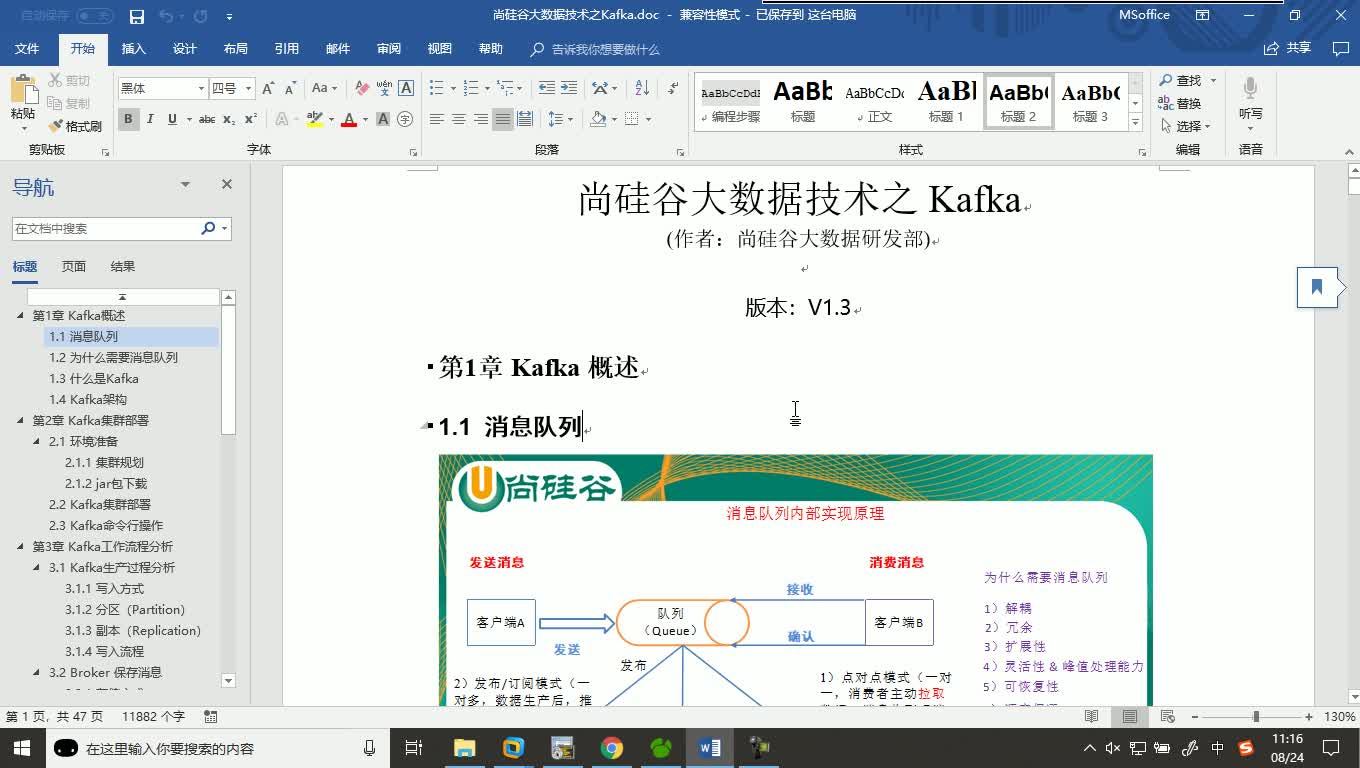 1980人 学习人数4.5分 课程评分新版全面系统完整的Kafka视频教程本教程由尚硅谷和张长志联合出品Kafka是一个开源流处理平台,由Scala和Java编写。Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据。在本课程中,你将学习到,Kafka架构原理、安装配置使用、详细的Kafka写入数据和处理数据以及写出数据的流程、新旧版本对比及运用、分区副本机制的详解、内部存储策略、高阶API直接消费数据、低阶API自行管理Offset消费数据、Kafka拦截器以及KafkaStream流式处理。购买后资料问题请加老师QQ 2020363447云计算/大数据大数据kafkaapiscala
1980人 学习人数4.5分 课程评分新版全面系统完整的Kafka视频教程本教程由尚硅谷和张长志联合出品Kafka是一个开源流处理平台,由Scala和Java编写。Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据。在本课程中,你将学习到,Kafka架构原理、安装配置使用、详细的Kafka写入数据和处理数据以及写出数据的流程、新旧版本对比及运用、分区副本机制的详解、内部存储策略、高阶API直接消费数据、低阶API自行管理Offset消费数据、Kafka拦截器以及KafkaStream流式处理。购买后资料问题请加老师QQ 2020363447云计算/大数据大数据kafkaapiscala
套餐介绍
Hadoop生态圈主要用来解决海量数据的存储和分析计算问题。是大数据开发工程师必备技术之一。
课程特点:
1、全程案例贯穿始终,几乎每个知识点都有配套的案例;
2、整个框架深入源码讲解;
3、优化措施全部来源于企业开发;
4、Hadoop生态圈相关企业真题全覆盖。
第一章 Hadoop、Zookeeper
第二章 数据仓库工具hive
第三章 HA
第四章 Flume
第五章 分布式数据库Hbase
第六章 批量数据迁移的工具Sqoop
第七章 批量工作流任务调度器Azkaban
第八章 任务调度框架Oozie
第九章 亚秒级查询工具Kylin







