自然语言处理--词向量视频教学(word embedding)

课时介绍
word2vec模型实现讲解-word2vec之Tensorflow实现自然语言处理--词向量视频教学(word embedding)
课程介绍
自然语言处理教程,该课程着重讲解词向量(Word embedding),词向量是深度学习技术在自然语言处理中应用的基础,因此掌握好词向量是学习深度学习技术在自然语言处理用应用的重要环节。本课程从One-hot编码开始,word2vec、fasttext到glove讲解词向量技术的方方面面,每个技术点环节都有相应的小案例,以增加同学们学习兴趣。同时在课程最后整合案例的方式给大家展示词向量技术在相似度计算中的典型应用。希望我们的课程能帮助更多的NLPper。
推荐课程

信息系统项目管理师自考笔记
李明 · 480人在学
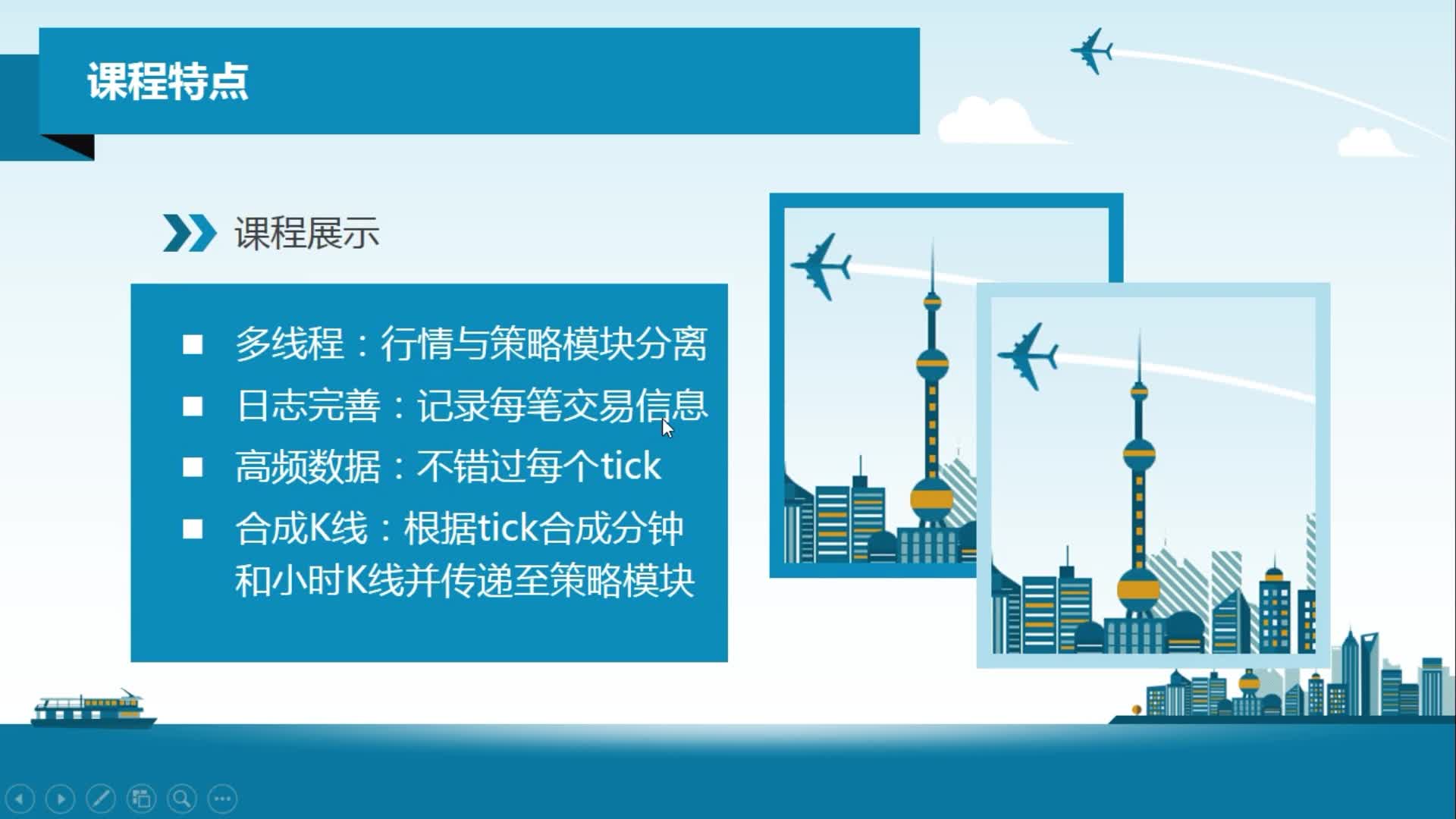
python从0到1:期货量化交易系统(CTP实战,高频及合成K线数据
王先生 · 19654人在学

手把手搭建Java超市管理系统【附源码】(毕设)
汤小洋 · 3980人在学
Java毕设springboot外卖点餐系统 毕业设计毕设源码 使用教
黄菊华 · 712人在学
基于SSM酒店管理系统(毕设)
小尼老师 · 760人在学
java项目实战之购物商城(java毕业设计)
Long · 5039人在学

手把手搭建Java求职招聘系统【附源码】(毕设)
汤小洋 · 1442人在学
Python Django 深度学习 小程序
钟翔 · 2204人在学

城管局门前三包管理系统+微信小程序(vue+springboot)
赖国荣 · 467人在学
Vue+Uni-app(uniapp)入门与实战+赠送仿美团点餐小程序
李杰 · 3793人在学