
掌握词向量技术,能够自然应用词向量框架word2vec、fasttext、glove。
自然语言处理--词向量视频教学(word embedding)
无限期 视频有效期
62节 节数
2867人 学习人数
课程评分
 分享
分享 

自然语言处理--词向量视频教学(word embedding)
自然语言处理教程,该课程着重讲解词向量(Word embedding),词向量是深度学习技术在自然语言处理中应用的基础,因此掌握好词向量是学习深度学习技术在自然语言处理用应用的重要环节。本课程从One-hot编码开始,word2vec、fasttext到glove讲解词向量技术的方方面面,每个技术点环节都有相应的小案例,以增加同学们学习兴趣。同时在课程最后整合案例的方式给大家展示词向量技术在相似度计算中的典型应用。希望我们的课程能帮助更多的NLPper。
复制链接
扫一扫
开发组长/高级工程师/技术专家
长期从事机器学习深度学习研究,在自然语言处理领域有一定认知
长期从事机器学习深度学习研究,在自然语言处理领域有一定认知
你将收获
适用人群
自然语言处理爱好者、自然语言处理从业者、人工智能从业者、机器学习从业者
课程介绍
自然语言处理教程,该课程着重讲解词向量(Word embedding),词向量是深度学习技术在自然语言处理中应用的基础,因此掌握好词向量是学习深度学习技术在自然语言处理用应用的重要环节。本课程从One-hot编码开始,word2vec、fasttext到glove讲解词向量技术的方方面面,每个技术点环节都有相应的小案例,以增加同学们学习兴趣。同时在课程最后整合案例的方式给大家展示词向量技术在相似度计算中的典型应用。希望我们的课程能帮助更多的NLPper。
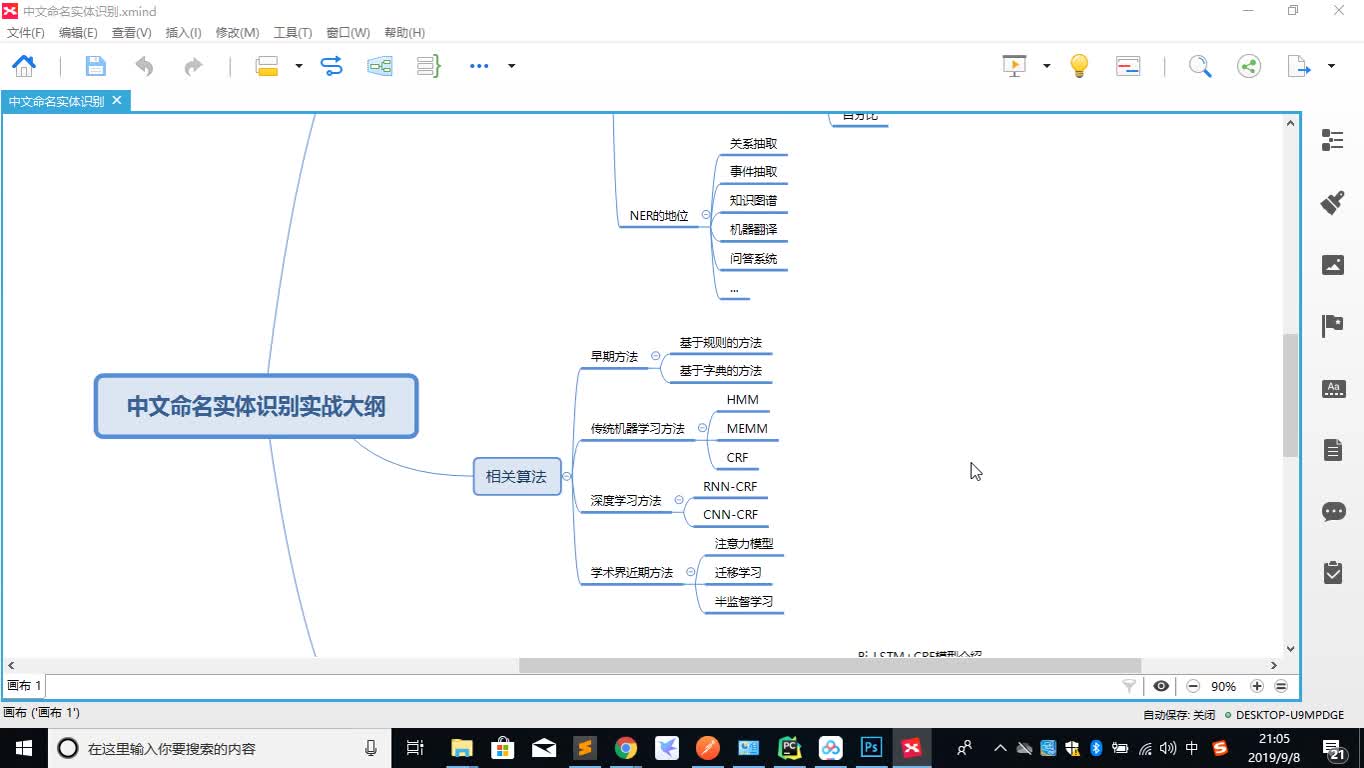
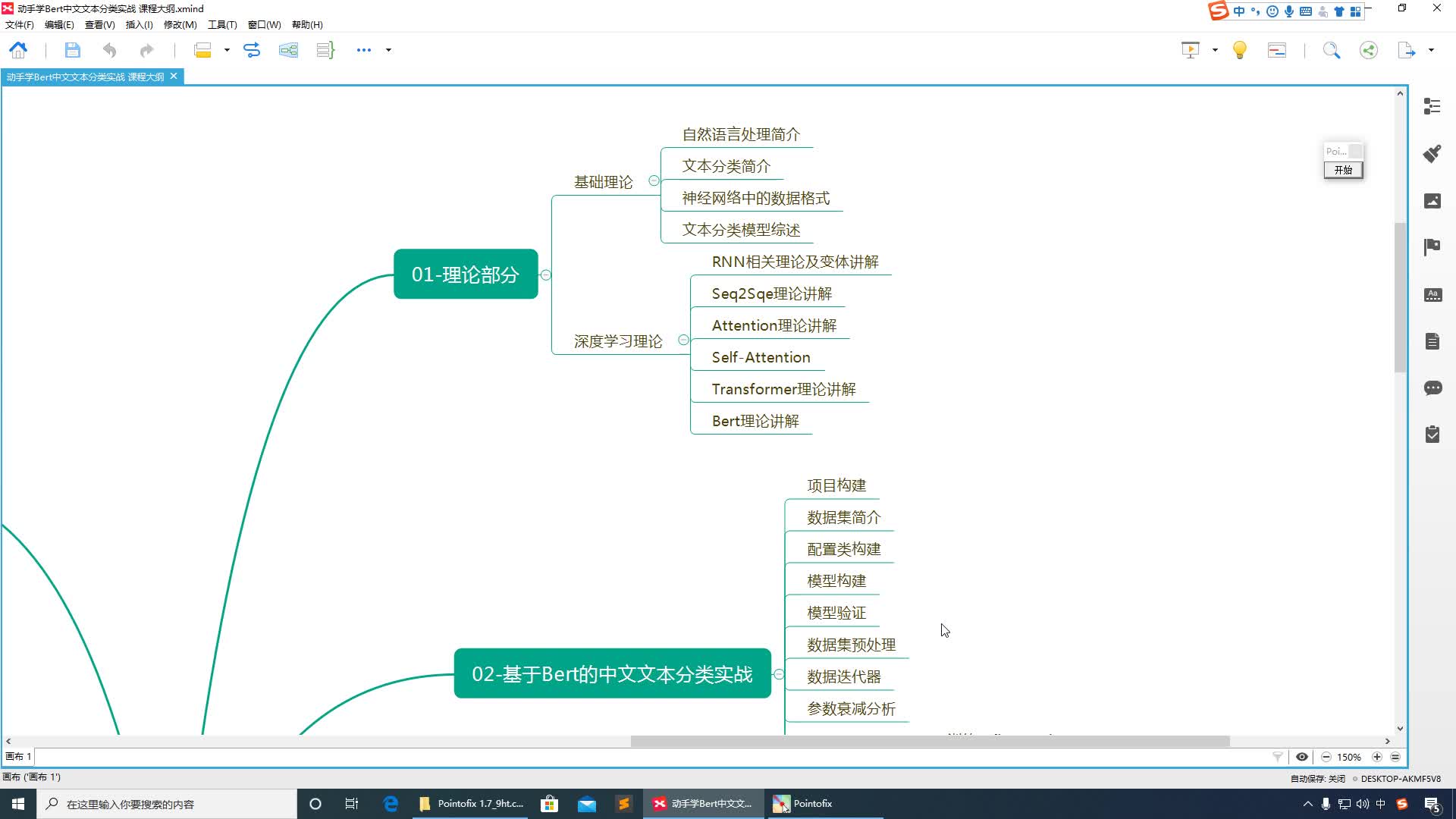
课程目录
推荐







资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈

