掌握Triton推理服务器上部署YOLOv8的方法
学习Triton推理服务器部署原理
学习Triton推理服务器上使用onnxruntime后端部署YOLOv8
学习Triton推理服务器上使用TensorRT后端部署YOLOv8
 分享
分享 

Triton推理服务器部署YOLOv8实战
你将收获
掌握Triton推理服务器上部署YOLOv8的方法
学习Triton推理服务器部署原理
学习Triton推理服务器上使用onnxruntime后端部署YOLOv8
学习Triton推理服务器上使用TensorRT后端部署YOLOv8
适用人群
课程介绍
Triton Inference Server(Triton 推理服务器)是一个高性能、灵活、可扩展的推理服务器,支持多种机器学习框架(PyTorch、ONNX等)和部署场景。
本课程讲述如何在Triton Inference Server(推理服务器)上部署YOLOv8目标检测的推理服务。 课程完整演示了在Ubuntu操作系统上使用Triton推理服务器的ONNX Runtime后端和TensorRT后端部署YOLOv8目标检测模型。
部署流程涵盖了以下关键步骤: 安装Docker、安装Nvidia Container Toolkit、导出ONNX模型、构建TensorRT引擎、组织模型仓库布局文件、构建Triton推理Docker容器、运行和测试Triton推理服务器。
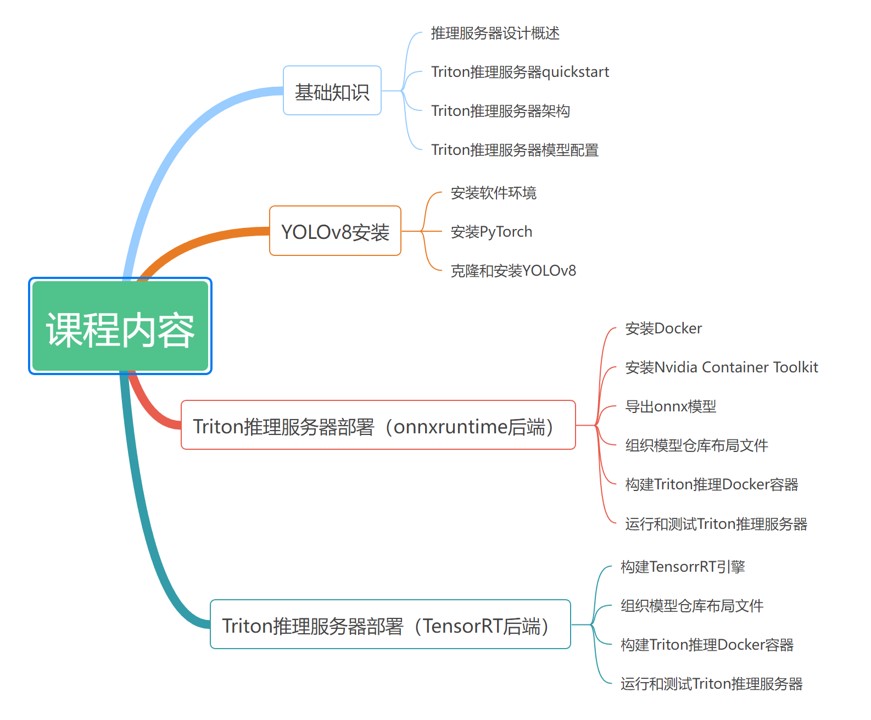
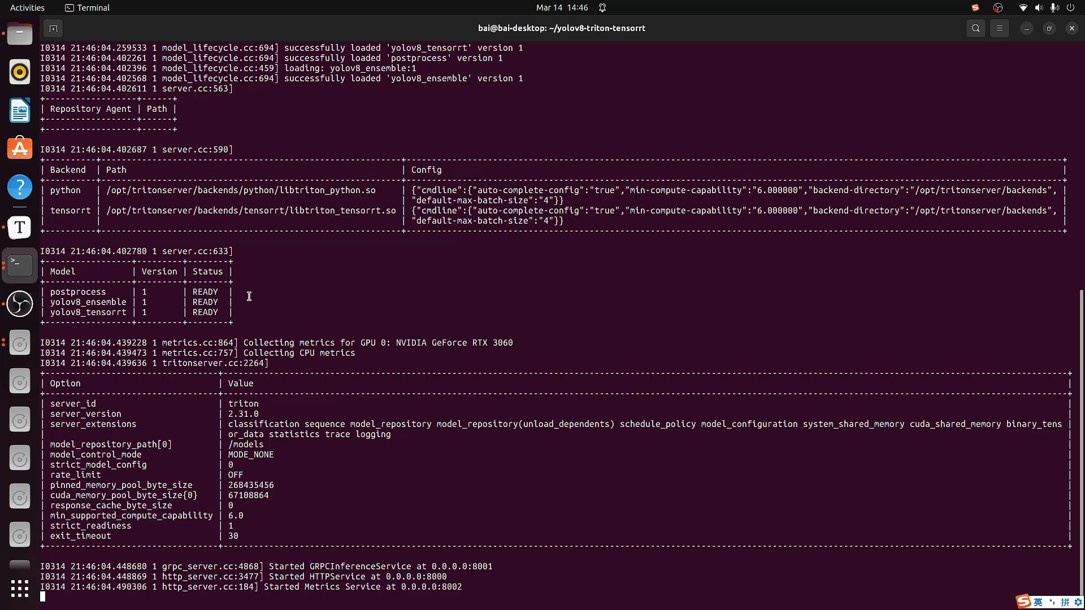
课程目录