在这个科技高速发展的时代,经历了PC时代几乎人手一台电脑,随之衍生出站长这个概念;移动互联网时代几乎人手一部智能手机,智能手机一般都会安装很多应用,目前应用呈爆发式的增长;随着产业的不断深入发展,小程序的发展也日益壮大,应用涵盖各个领域;如今一个公司就可能有多个软件应用,对于软件开发商来说,急需一套分析系统帮助软件运营,如果单独开发一个分析系统去针对一个软件进行分析的话,成本会非常的大,这个成本包含开发成本以及以后的维护成本。
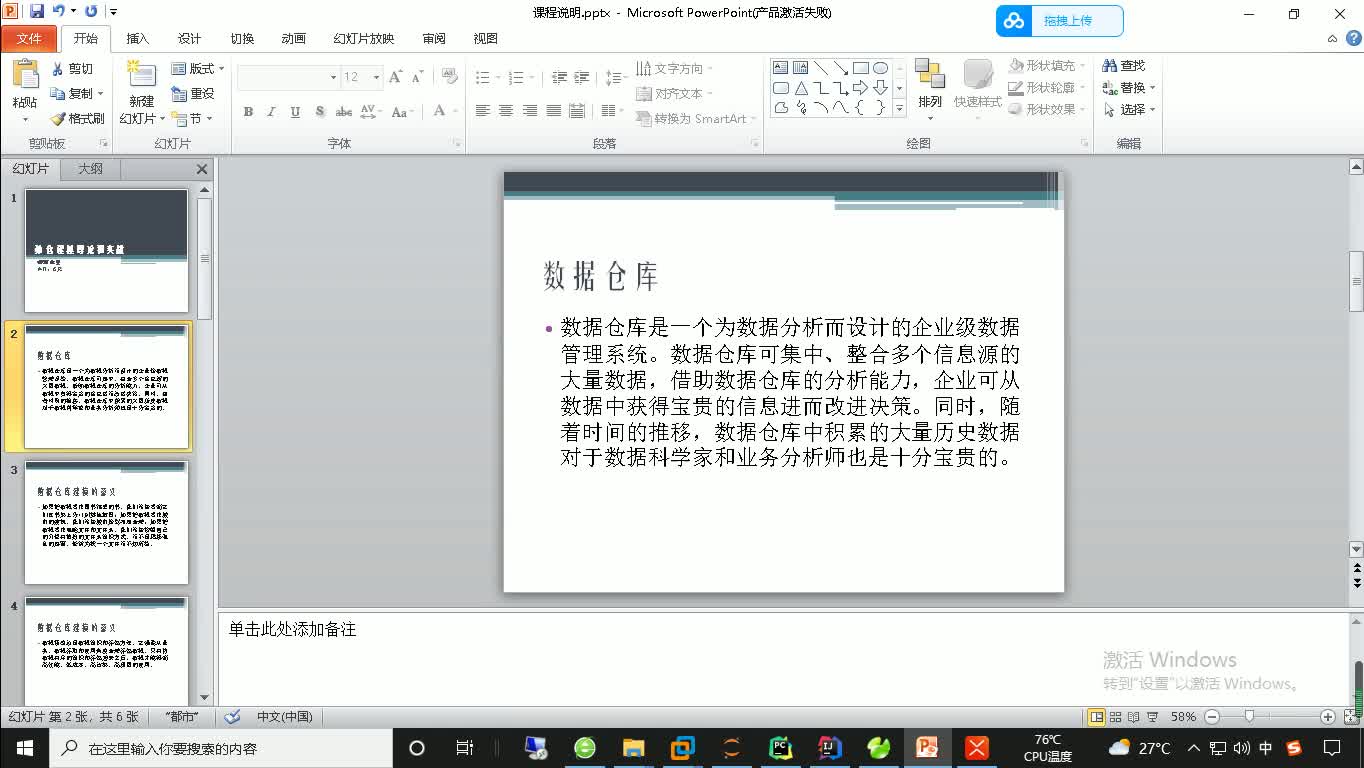
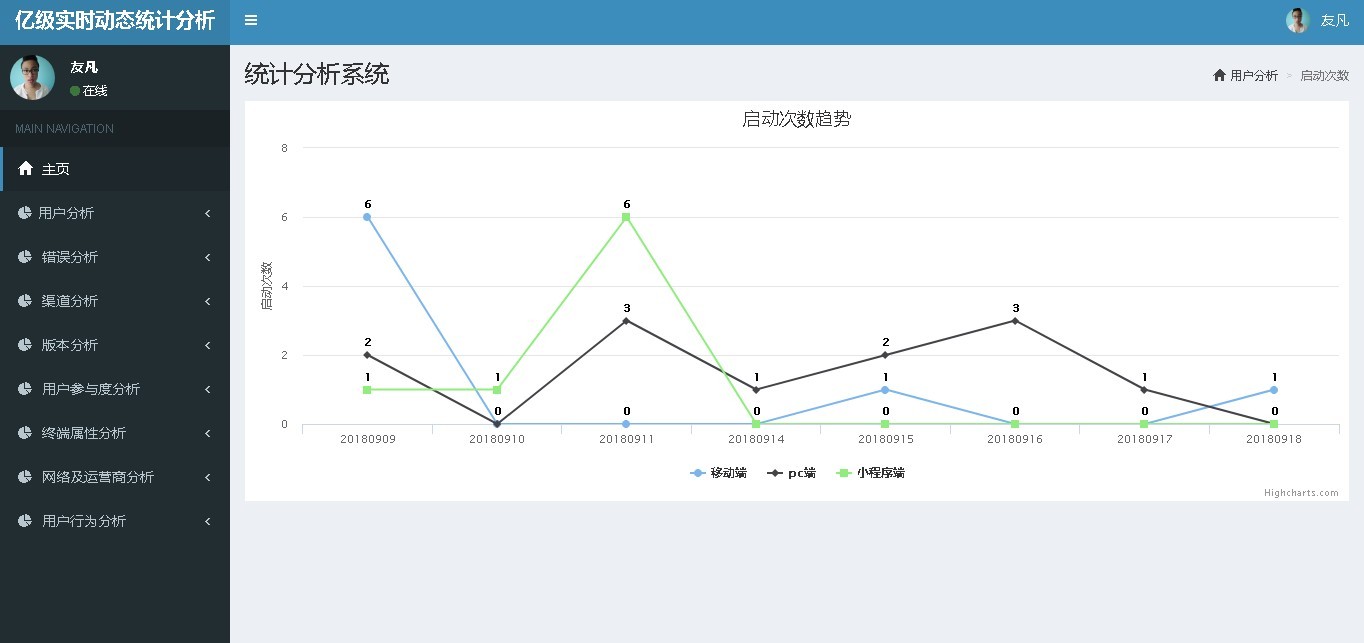
为了解决了上述的问题,我们开发出了一套云产品:亿级动态数据统计分析系统,本系统可以支持所有的终端 (Web端、移动端、小程序端等 )数据统计,只要简单的使用sdk就可以接入我们的系统,软件开发商可以很轻松的对软件使用的情况进行监控,及时辅助公司对该软件的运营。该产品历经2年的实践,商业价值极高。
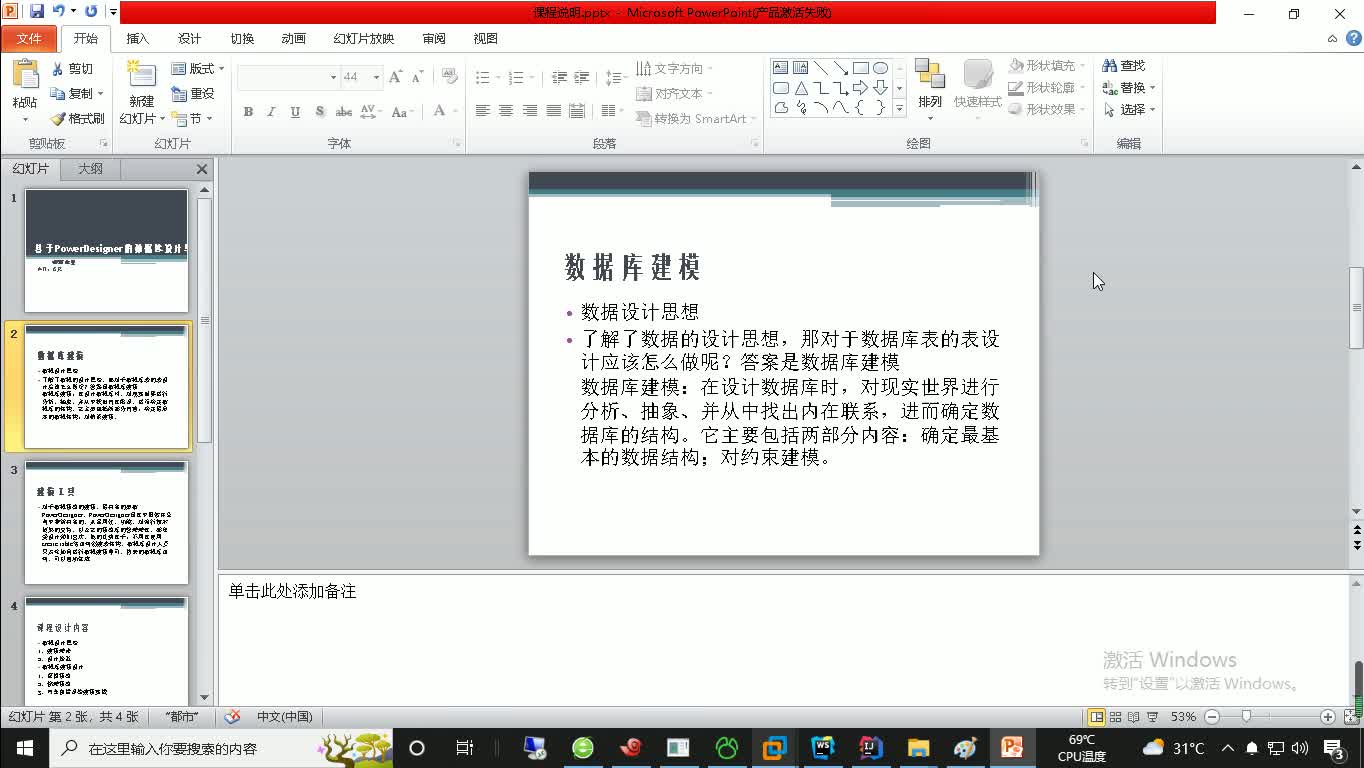
本套案例是完全基于真实的产品进行开发和讲解的,同时对架构进行全面的升级,采用了全新的 Flink 架构+Node.js+Vue.js等,完全符合目前企业级的使用标准。对于本套课程在企业级应用的问题,可以提供全面的指导。
Flink作为第四代大数据计算引擎,越来越多的企业在往Flink转换。Flink在功能性、容错性、性能方面都远远超过其他计算框架,兼顾高吞吐和低延时。
Flink能够基于同一个Flink运行时,提供支持流处理和批处理两种类型应用的功能。也就是说同时支持流处理和批处理。Flink将流处理和批处理统一起来,也就是说作为流处理看待时输入数据流是无界的;批处理被作为一种特殊的流处理,只是它的输入数据流被定义为有界的。
Flink技术特点
1. 流处理特性
支持高吞吐、低延迟、高性能的流处理
支持带有事件时间的窗口(Window)操作
支持有状态计算的Exactly-once语义
支持高度灵活的窗口(Window)操作,支持基于time、count、session,以及data-driven的窗口操作
支持具有Backpressure功能的持续流模型
支持基于轻量级分布式快照(Snapshot)实现的容错
一个运行时同时支持Batch on Streaming处理和Streaming处理
Flink在JVM内部实现了自己的内存管理支持迭代计算
支持程序自动优化:避免特定情况下Shuffle、排序等昂贵操作,中间结果有必要进行缓存
2. API支持
对Streaming数据类应用,提供DataStream API
对批处理类应用,提供DataSet API(支持Java/Scala)
3. Libraries支持
支持机器学习(FlinkML)
支持图分析(Gelly)
支持关系数据处理(Table)
支持复杂事件处理(CEP)
4. 整合支持
支持Flink on YARN
支持HDFS
支持来自Kafka的输入数据
支持Apache HBase
支持Hadoop程序
支持Tachyon
支持ElasticSearch
支持RabbitMQ
支持Apache Storm
支持S3
支持XtreemFS
课程所涵盖的知识点包括:Flink、 Node.js、 Vue.js、 Kafka、Flume、Spring、SpringMVC、Dubbo、HDFS、Hbase、Highcharts等等
企业一线架构师讲授,代码在老师指导下可以复用,提供企业解决方案。
版权归作者所有,盗版将进行法律维权。

 分享
分享