Hadoop、Spark、Flink、Kafka到Docker、K8s
Hadoop、Spark、Flink、Kafka到Docker、K8s
课程开篇
【2025版】NoSQL课程更新
【2025版】容器课程更新
(大数据基础-00)大数据技术先导课程
(大数据基础-01)大数据技术思想与原理入门
(大数据基础-02)部署大数据实验环境
(Hadoop-01)分布式文件系统HDFS
- 01-使用Web Console操作HDFS
- 02-使用命令行操作HDFS
- 03-使用Java API创建目录以及目录的权限问题
- 04-使用Java API完成数据文件的上传和下载
- 05-使用Java API操作HDFS
- 06-主节点NameNode的职责
- 07-从节点DataNode的职责和数据上传的过程
- 08-数据下载的过程
- 09-SecondaryNameNode的职责
- 10-HDFS的高级特性之回收站
- 11-HDFS的高级特性之快照
- 12-HDFS的高级特性之配额管理
- 13-HDFS的高级特性之安全模式
- 14-HDFS的高级特性之权限管理
- 15-基于ViewFS实现HDFS的联盟
- 16-基于ViewFS部署HDFS联盟
- 17-基于RBF实现HDFS的联盟
- 18-基于RBF部署HDFS联盟
- 19-HDFS的底层通信方式:RPC
(Hadoop-02)分布式计算模型MapReduce与Yarn
- 01-分布式计算模型课程简介
- 02-分析WordCount数据处理的过程
- 03-开发自己的WordCount程序
- 04-开发案例-求每个部门的工资总和
- 05-Yarn调度MapReduce任务的过程
- 06-Yarn的资源分配方式
- 07-序列化
- 08-基本数据类型的排序
- 09-对象的排序
- 10-分区的基本知识
- 11-实现MapReduce的自定义分区
- 12-在MapReduce中使用Combiner
- 13-MapReduce的MapJoin
- 14-MapReduce的链式处理
- 15-MapReduce Shuffle洗牌
- 16-数据去重
- 17-等值连接的多表查询数据处理的过程
- 18-使用MapReduce实现等值连接
- 19-自连接的多表查询数据处理的过程
- 20-使用MapReduce实现自连接操作
- 21-分析倒排索引的创建过程
- 22-使用MapReduce实现倒排索引
(Hadoop-03)列式NoSQL数据库HBase
- 01-HBase课程简介
- 02-HBase中的基本概念
- 03-HBase的体系架构
- 04-部署HBase的本地模式
- 05-部署HBase的伪分布模式
- 06-部署HBase的全分布模式和HA模式
- 07-使用命令行工具和Web操作HBase
- 08-使用Java API操作HBase
- 09-HBase上的MapReduce
- 10-使用的HBase过滤器
- 11-HBase写入数据的机制
- 12-HBase读取数据的机制
- 13-HBase的其他运行机制
- 14-HBase多版本Version
- 15-HBase的快照
- 16-HBase的Bulk Loading
- 17-HBase的用户权限管理
- 18-HBase备份与恢复
- 19-HBase的主从复制
- 20-HBase集群监控基础
- 21-利用可视化工具监控HBase
- 22-HBase的预分区
- 23-HBase数据的生命周期
- 24-HBase资源的配额Quota
- 25-Phoenix简介和安装配置
- 26-在Phoenix中使用二级索引
- 27-在Phoenix中执行JDBC
(Hadoop-04)数据分析引擎Hive
- 01-Hive课程简介
- 02-Hive简介
- 03-Hive的体系架构
- 04-部署Hive的嵌入模式
- 05-部署Hive的远程模式
- 06-Hive的内部表
- 07-Hive的外部表
- 08-Hive的静态分区表
- 09-Hive的动态分区表
- 10-Hive的桶表
- 11-Hive的临时表
- 12-Hive的视图
- 13-Hive的字符函数
- 14-Hive的数值函数
- 15-Hive的日期函数
- 16-Hive的条件函数
- 17-Hive的开窗函数
- 18-Hive的URL和JSON解析函数
- 19-开发Hive的用户自定义函数
- 20-开发Hive的用户自定义表生成函数
- 21-Hive的JDBC客户端
- 22-Presto简介与体系架构
- 23-安装部署Presto
- 24-Presto执行查询的过程
(Hadoop-05)分布式协调服务ZooKeeper
(Hadoop-06)数据采集引擎Sqoop&Flume
(Spark-01)离线计算引擎Spark Core
- 01-Spark课程简介
- 02-什么是Spark?
- 03-Spark的体系架构
- 04-使用spark-submit提交Spark任务
- 05-使用spark-shell执行Spark任务
- 06-Spark HA之基于文件系统的单点恢复
- 07-基于ZooKeeper实现Spark的HA
- 08-什么是Spark RDD?
- 09-使用Transformation的基础算子
- 10-使用mapPartitionsWithIndex
- 11-使用aggregate和aggregateByKey
- 12-使用coalesce与repartition算子
- 13-使用Action算子
- 14-RDD的依赖关系和任务执行的阶段
- 15-RDD的检查点机制
- 16-RDD的缓存机制
- 17-开发Scala版本的WordCount程序
- 18-分析Spark WordCount数据处理的过程
- 19-开发Java版本的WordCount程序
- 20-求网站访问量的PV值
- 21-创建自定义分区
- 22-在Spark中访问数据库
(Spark-02)数据分析引擎Spark SQL
(Spark-03)流处理引擎Spark Streaming
(Flink01)大数据计算引擎Flink基础
- 01-Flink基础课程概述
- 02-Flink的体系架构
- 03-运行Flink的任务
- 04-Flink on Yarn
- 05-对比Flink、Storm、Spark Streaming
- 06-使用Java开发WordCount批处理计算任务
- 07-使用Java开发WordCount流处理计算任务
- 08-使用Scala开发WordCount批处理计算任务
- 09-使用Scala开发WordCount流处理计算任务
- 10-使用map、flatMap与mapPartition
- 11-使用filter与distinct
- 12-使用First-N
- 13-使用笛卡尔积
- 14-使用Join操作
- 15-使用外连接操作
- 16-使用基本的数据源
- 17-自定义单并行度数据源
- 18-自定义多并行度数据源
- 19-使用union的算子
- 20-使用connect算子
- 21-使用split和connect算子
- 22-使用Redis Sink保存数据
- 23-使用TimeWindow
- 24-使用CountWindow
- 25-Flink的时间
- 26-Watermark水位线机制
- 27-水位线WaterMark编程案例
- 28-Flink HA的架构与部署
(Flink02)大数据计算引擎Flink进阶
- 01-Flink进阶课程概述
- 02-Flink的并行度分析
- 03-使用Flink的分布式缓存
- 04-使用广播变量
- 05-使用累加器与计数器
- 06-Flink的状态管理
- 07-检查点与后端存储
- 08-Flink的重启策略
- 09-使用Table API开发Java版本的批处理WordCount
- 10-使用Table API开发Java版本的流处理WordCount
- 11-使用Table API开发Scala版本的批处理WordCount
- 12-使用Table API开发Scala版本的流处理WordCount
- 13-使用SQL API开发Java版本的批处理WordCount
- 14-使用SQL API开发Java版本的流处理WordCount
- 15-使用SQL API开发Scala版本的批处理WordCount
- 16-使用SQL API开发Scala版本的流处理WordCount
- 17-基于Flink的流批一体架构
大数据消息系统Kafka
- 01-Kafka课程概述
- 02-消息系统概述
- 03-消息系统的分类
- 04-Kafka的体系架构
- 05-主题、分区与副本
- 06-Kafka的生产者
- 07-Kafka的消费者
- 08-部署Kafka单机单Broker模式
- 09-部署Kafka单机多Broker模式
- 10-部署Kafka多机多Broker模式
- 11-使用命令行工具测试Kafka
- 12-Kafka配置参数详解
- 13-Kafka在ZooKeeper中存储的元数据
- 14-开发Java版本的客户端程序
- 15-开发Scala版本的客户端程序
- 16-发布与订阅自定义消息
- 17-消息的持久化
- 18-消息的传输保障
- 19-Leader的选举
- 20-Kafka的日志清理
- 21-集成Flume与Kafka
- 22-基于Spark Streaming接收器方式集成Kafka
- 23-基于Spark Streaming直接读取方式
- 24-将Kafka作为Flink的Source Connector
- 25-将Kafka作为Flink的Sink Connector
(Redis-01)架构实战
(Redis-02)数据结构剖析
(Redis-03)工作机制剖析
(Redis-04)高级特性原理
(Redis-05)集群高可用实战
- 01-主从复制的架构与配置
- 02-主从复制的通信过程
- 03-主从复制的源码分析
- 04-部署Redis的哨兵
- 05-Redis哨兵的主要配置参数
- 06-哨兵工作原理剖析
- 07-什么是Redis Cluster
- 08-数据分布理论与Redis的数据分区
- 09-Redis Cluster的体系架构
- 10-一致性Hash算法
- 11-手动部署Redis Cluster
- 12-使用脚本create-cluster部署RedisCluste
- 13-操作与管理Redis Cluster
- 14-实现Redis Cluster的代理分片
- 15-Codis的体系架构和组件说明
- 16-安装go语言环境
- 17-02-安装部署Codis集群
- 18-基于Codis的主从复制
- 19-基于Codis的数据分布式存储
(Redis-06)企业解决方案剖析
(MongoDB-01)体系结构
(MongoDB-02)安装和管理配置
(MongoDB-03)数据类型
(MongoDB-04)基本操作
(MongoDB-05)聚合操作
(MongoDB-06)存储引擎原理
(MongoDB-07)索引和分析
(MongoDB-08)主从复制与主备切换
(MongoDB-09)数据分布式存储
(MongoDB-10)监控和备份
(MongoDB-11)数据模型
(Docker-01)基础篇
- 01-Docker的基础篇概述
- 02-什么是Docker及其体系架构
- 03-安装和配置Docker实验环境
- 04-什么是Docker镜像
- 05-使用和访问官方的Docker的镜像仓库
- 06-配置和使用阿里云提供的Docker镜像加速器
- 07-管理Docker镜像
- 08-使用docker_commit和Dockerfile
- 09-Dockerfile使用和综合案例
- 10-容器的基本操作
- 11-Docker的日志
- 12-资源管理基础知识Linux CGroup
- 13-Docker对容器使用CPU使用率的管理
- 14-Docker对容器使用的内存管理和限制
- 15-Docker对容器使用I/O的管理和限制
- 16-Docker网络通信的基本原理
- 17-Docker的网络模式
- 18-容器间的通信
- 19-容器访问控制
- 20-Docker的数据卷
- 21-Docker的数据卷容器
- 22-利用数据卷容器来实现数据的迁移
- 23-Docker与数据库
- 24-Docker与nginx
- 25-Docker与PHP
- 26-Docker与Python
- 27-Docker与Jupyter_Notebook
- 28-Docker与TensorFlow
- 29-Docker与OpenStack
- 30-什么是Harbor
- 31-安装和配置Harbor
- 32-配置Docker客户机并验证环境
(Docker-02)高级篇
- 00-Docker高级篇课程概述
- 01-什么是Docker Machine和安装配置
- 02-在远程主机上安装和管理Docker
- 03-使用docker-machine创建基于virtualbox的虚拟容器
- 04-使用docker-machine创建基于vsphere的虚拟容器
- 05-Docker Compose的概述和安装
- 06-通过手动方式部署Web应用
- 07-通过docker-compose方式部署Web应用
- 08-什么是yml文件
- 09-使用Docker-Compose进行服务的在线扩容和缩容
- 10-Swarm的体系架构与安装配置
- 11-在Swarm集群上部署应用
- 12-实现服务的滚动更新
- 13-Swarm集群的数据持久化
- 14-集群的负载均衡的实现
- 15-什么是Jenkins及其安装配置
- 16-使用Jenkins持续部署一个Java程序
- 17-集成Docker与Jenkins
- 18-什么是服务的注册和发现
- 19-服务的注册中心Consul的配置和使用
- 20-实现Docker容器服务的注册和发现
- 21-DockerUI
- 22-Portainer
- 23-Shipyard
(K8s-01)体系架构
(K8s-02)部署K8s集群
(K8s-03)最小可部署对象Pod
(K8s-04)使用控制器管理Pod
(K8s-05)通过Service访问Pod
(K8s-06)持久化存储
(K8s-07)安全认证
(K8s-08)日志收集与监控
(K8s-09)集成与运维管理
课程资料下载
【2026版】大数据数据湖Hudi与Spark
【2026版】NoSQL课程更新
【2026版】容器课程更新

馈,我们将及时处理!
课时介绍
课程介绍



信息系统项目管理师自考笔记
李明 · 984人在学
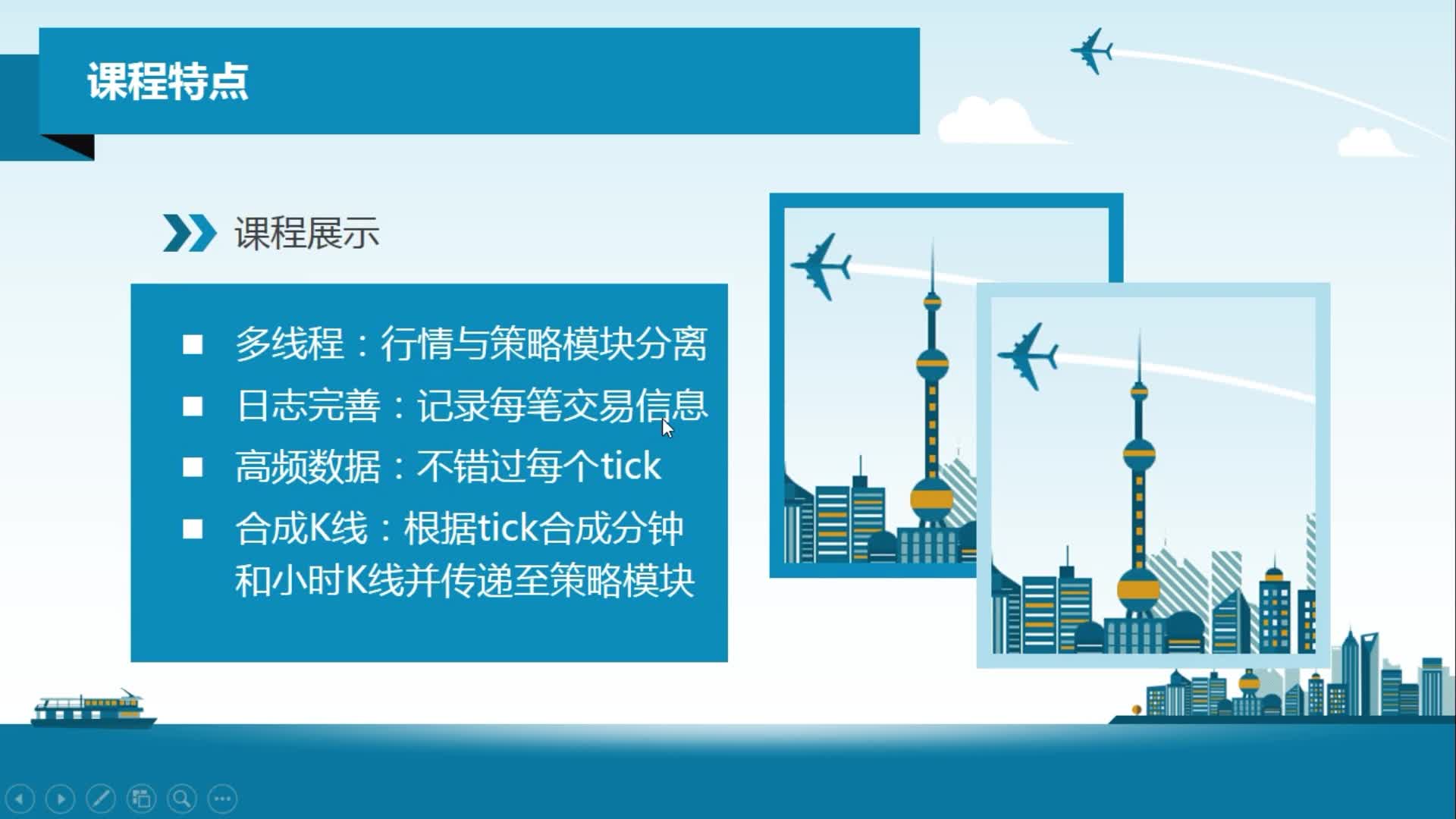
python从0到1:期货量化交易系统(CTP实战,高频及合成K线数据
王先生 · 23085人在学

手把手搭建Java超市管理系统【附源码】(毕设)
汤小洋 · 4326人在学
Java毕设springboot外卖点餐系统 毕业设计毕设源码 使用教
黄菊华 · 853人在学
基于SSM酒店管理系统(毕设)
小尼老师 · 915人在学
java项目实战之购物商城(java毕业设计)
Long · 5219人在学

手把手搭建Java求职招聘系统【附源码】(毕设)
汤小洋 · 1543人在学
Python Django 深度学习 小程序
钟翔 · 2443人在学

城管局门前三包管理系统+微信小程序(vue+springboot)
赖国荣 · 719人在学
Vue+Uni-app(uniapp)入门与实战+赠送仿美团点餐小程序
李杰 · 4108人在学