基于阿里云的海量数据处理数据仓库(离线)实战教程
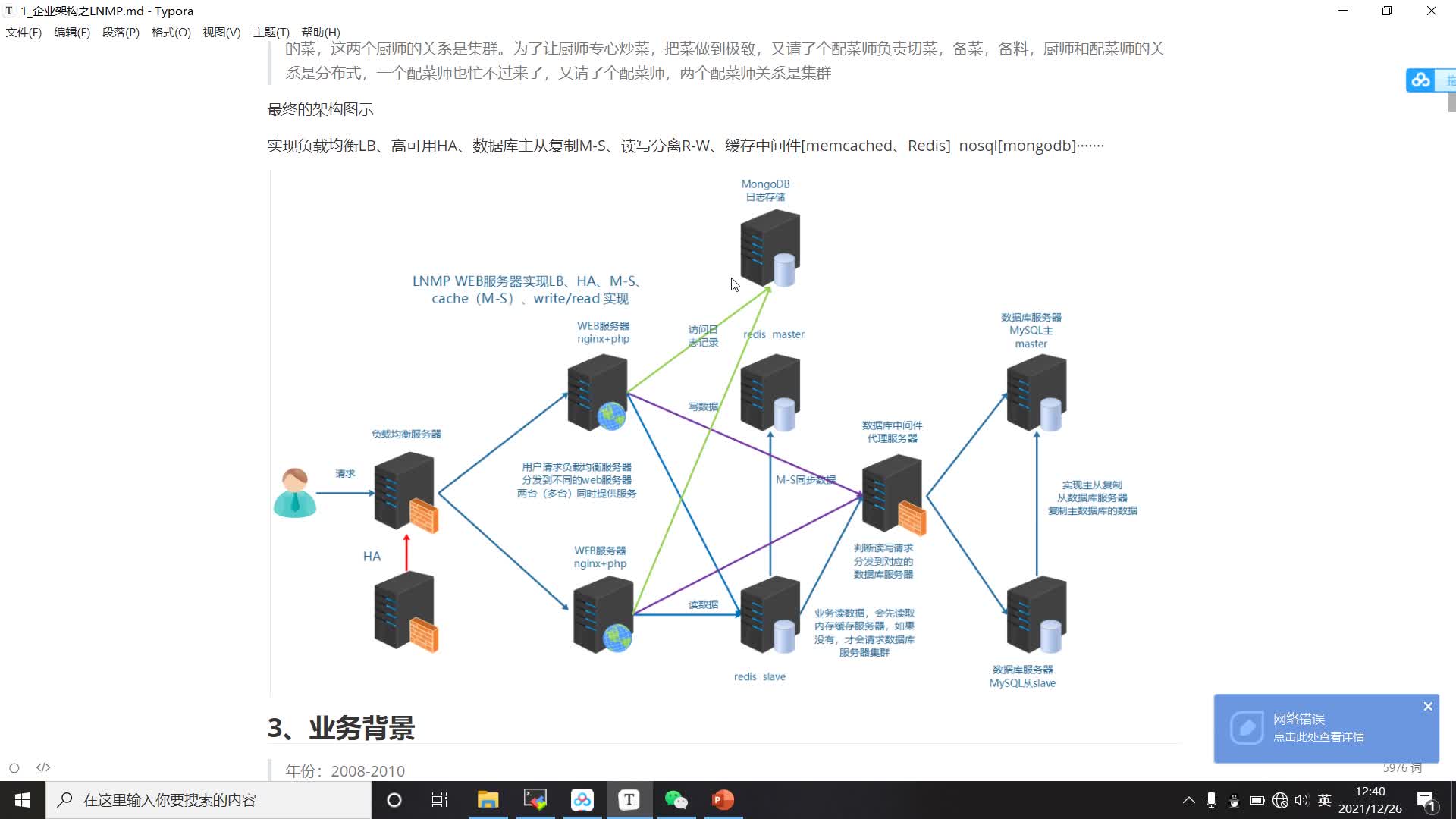
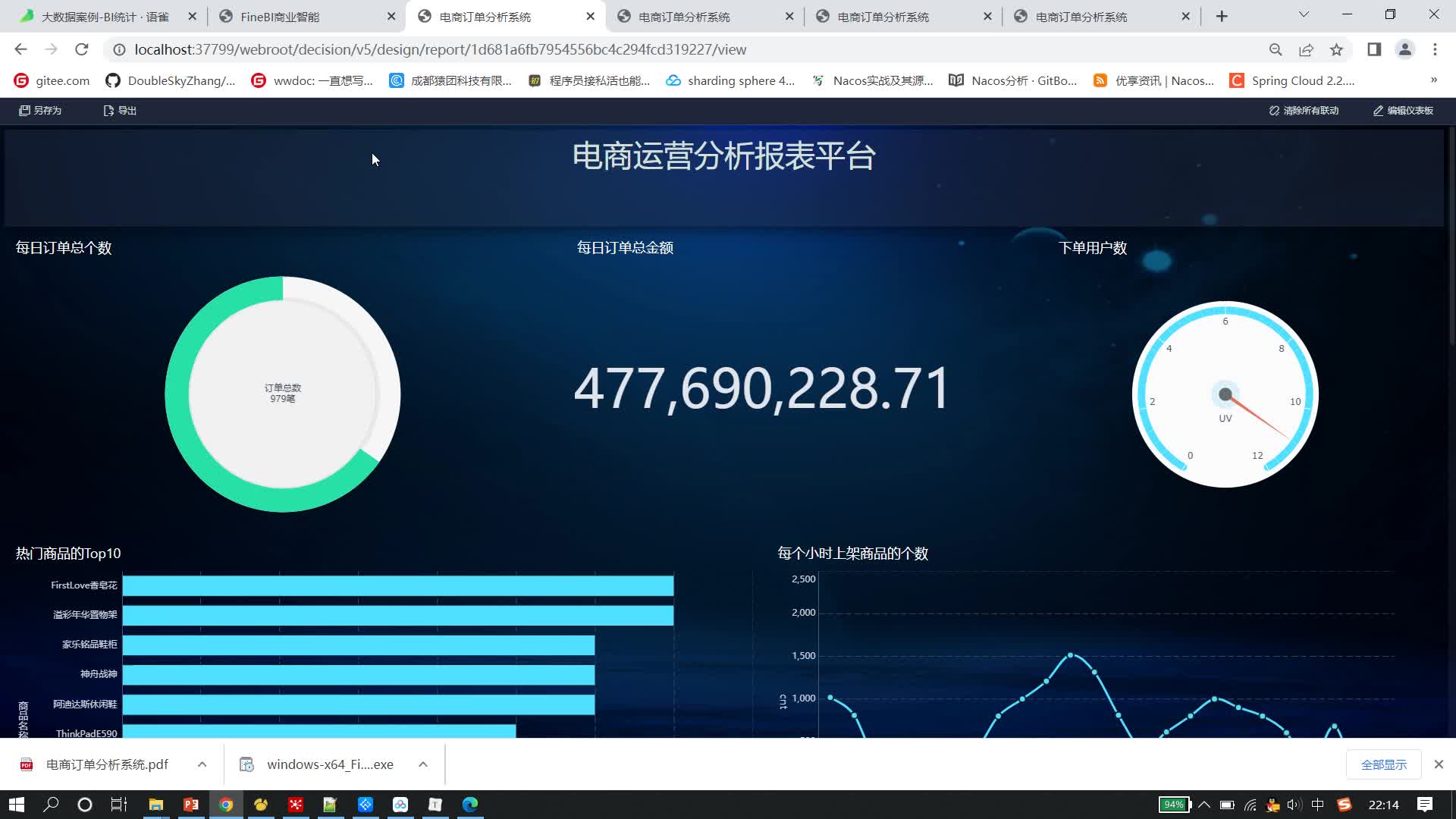
一、项目简介 本项目教程以国内电商巨头实际业务应用场景为依托,同时以阿里云ECS服务器为技术支持,紧跟大数据主流场景,对接企业实际需求,对电商数仓的常见实战指标进行了详尽讲解,让你迅速成长,获取最前沿的技术经验。 二、项目架构 版本框架:Flume、DateHub、DataWorks、MaxCompute、MySql以及QuickBI等; Flume:大数据领域被广泛运用的日志采集框架; DateHub:类似于传统大数据解决方案中Kafka的角色,提供了一个数据队列功能。对于离线计算,DataHub除了供了一个缓冲的队列作用。同时由于DataHub提供了各种与其他阿里云上下游产品的对接功能,所以DataHub又扮演了一个数据的分发枢纽工作; 据上传和下载通道,提供SQL及MapReduce等多种计算分析服务,同时还提供完善的安全解决方案; DataWorks:是基于MaxCompute计算引擎,从工作室、车间到工具集都齐备的一站式大数据工厂,它能帮助你快速完成数据集成、开发、治理、服务、质量、安全等全套数据研发工作; QuickBI & DataV:专为云上用户量身打造的新一代智能BI服务平台。 三、项目场景 数仓项目广泛应用于大数据领域,该项目技术可以高度适配电商、金融、医疗、在线教育、传媒、电信、交通等各领域; 四、项目特色 本课程结合国内多家企业实际项目经验。从集群规模的确定到框架版本选型以及服务器选型,手把手教你从零开始搭建基于阿里云服务器的大数据集群。采用阿里云ECS服务器作为数据平台,搭建高可用的、高可靠的Flume数据采集通道,运用阿里云DateHub构建中间缓冲队列并担任数据分发枢纽将数据推送至阿里自主研发的DataWorks对数据进行分层处理,采用MaxCompute作为处理海量数据的方案,将计算结果保存至MySQL并结合阿里的QuickBI工作做最终数据展示。
复制链接

 分享
分享