【系统完整】大数据项目实战就业课程|离线|实时|数仓|推荐|数据可视化

课时介绍
课程介绍
1.课程介绍
本课程为《实战大数据(hadoop+spark+flink)》书籍配套的项目实战教程,以大数据实战项目为主线,理论和实战相结合,全方位、全流程、无死角讲解大数据项目的项目需求分析、技术选型、架构设计、集群规划、安装部署、大数据项目开发以及数据可视化。
本课程包含Hadoop、Spark、Flink等主流实用大数据技术,涵盖离线计算、实时计算、数据仓库、推荐系统、数据可视化等主流大数据项目。
学完本课程,零基础的学员能快速入行大数据,独立完成大数据项目开发;有开发基础的小伙伴也能积累各类大数据项目实战经验,快速成为大数据全栈工程师。
2.课程特色
(1)课程以实战项目为主线,理论与项目实战交替讲解,层层递进。
(2)课程从理论原理、环境配置、服务安装、组件集成开发、业务代码开发、可视化等项目完整流程讲解,不会跳讲和断讲。
(3)课程中无论案例代码开发还是项目业务代码开发,每一行代码都会边敲边讲解。
(4)大数据各个技术组件版本选择、下载、安装、配置都会一一讲解到位。
(5)课程使用目前稳定技术版本,如Hadoop3.3.3、Spark3.1.3、Flink1.20
3.课程资料
(1)提供完整安装包
(2)提供完整集群配置文件
(3)提供完整项目数据集
(4)提供集群脚本
(5)提供数据库建表SQL
(6)提供完整工程源码
(7)提供完整课程PPT
(8)提供完整课程集群word文档
4.大数据项目可视化效果图
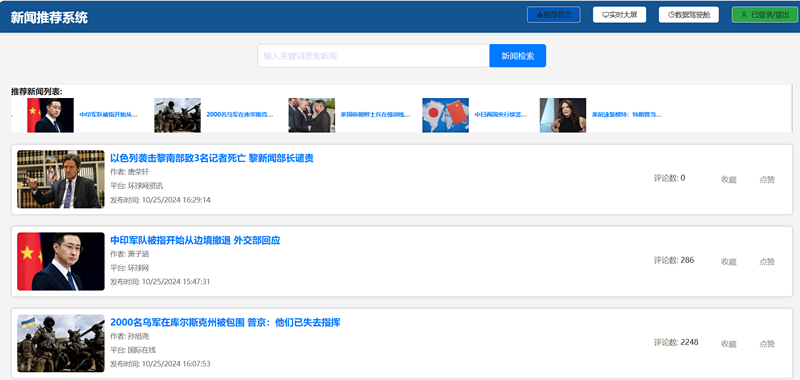
新闻资讯列表展示
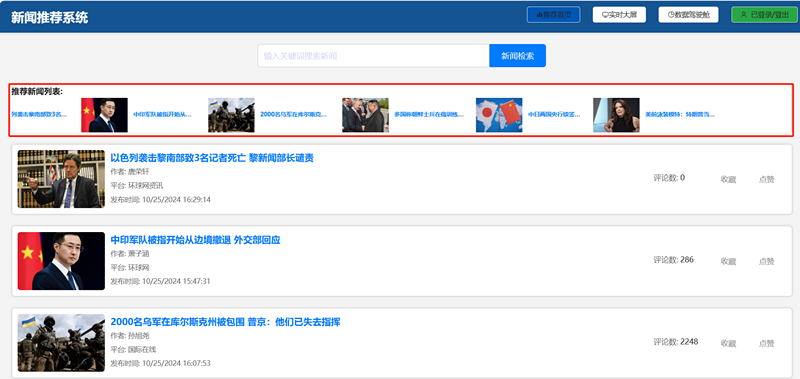
个性化推荐
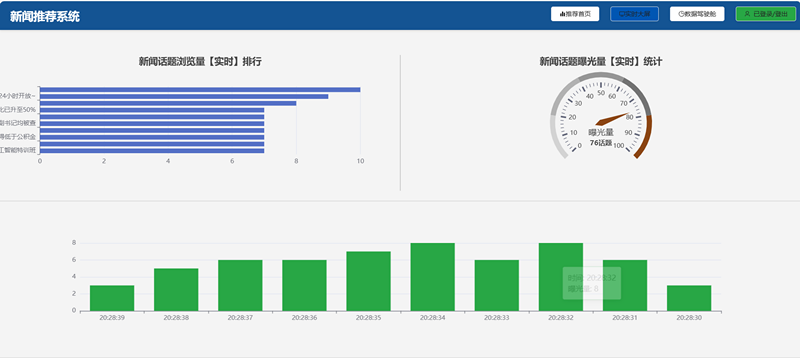
数据大屏展示
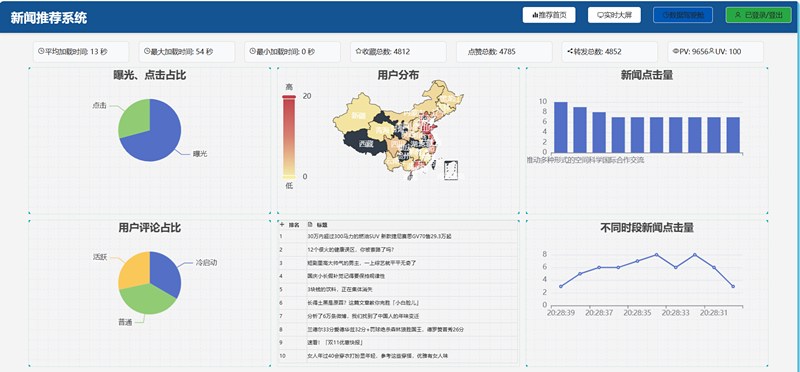
数据仓库驾驶舱


信息系统项目管理师自考笔记
李明 · 1016人在学
python从0到1:期货量化交易系统(CTP实战,高频及合成K线数据
王先生 · 23143人在学

手把手搭建Java超市管理系统【附源码】(毕设)
汤小洋 · 4331人在学
Java毕设springboot外卖点餐系统 毕业设计毕设源码 使用教
黄菊华 · 857人在学
基于SSM酒店管理系统(毕设)
小尼老师 · 926人在学
java项目实战之购物商城(java毕业设计)
Long · 5225人在学

手把手搭建Java求职招聘系统【附源码】(毕设)
汤小洋 · 1547人在学
Python Django 深度学习 小程序
钟翔 · 2447人在学

城管局门前三包管理系统+微信小程序(vue+springboot)
赖国荣 · 730人在学
Vue+Uni-app(uniapp)入门与实战+赠送仿美团点餐小程序
李杰 · 4118人在学