python机器学习-乳腺癌细胞挖掘

课时介绍
课程介绍
作者介绍
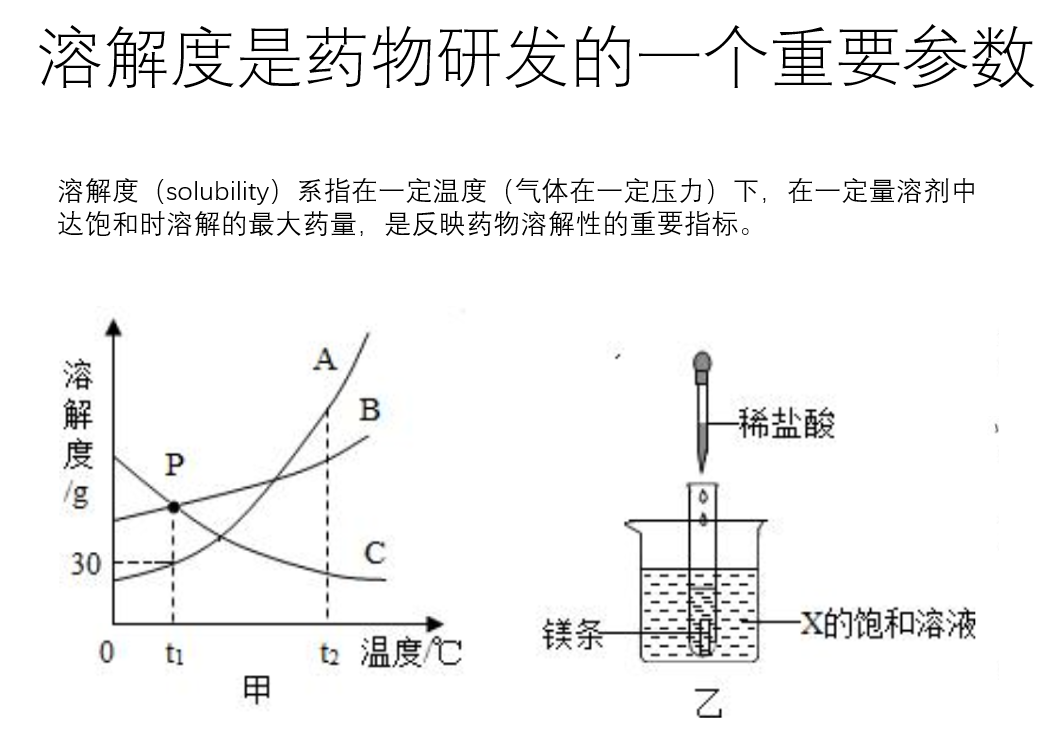
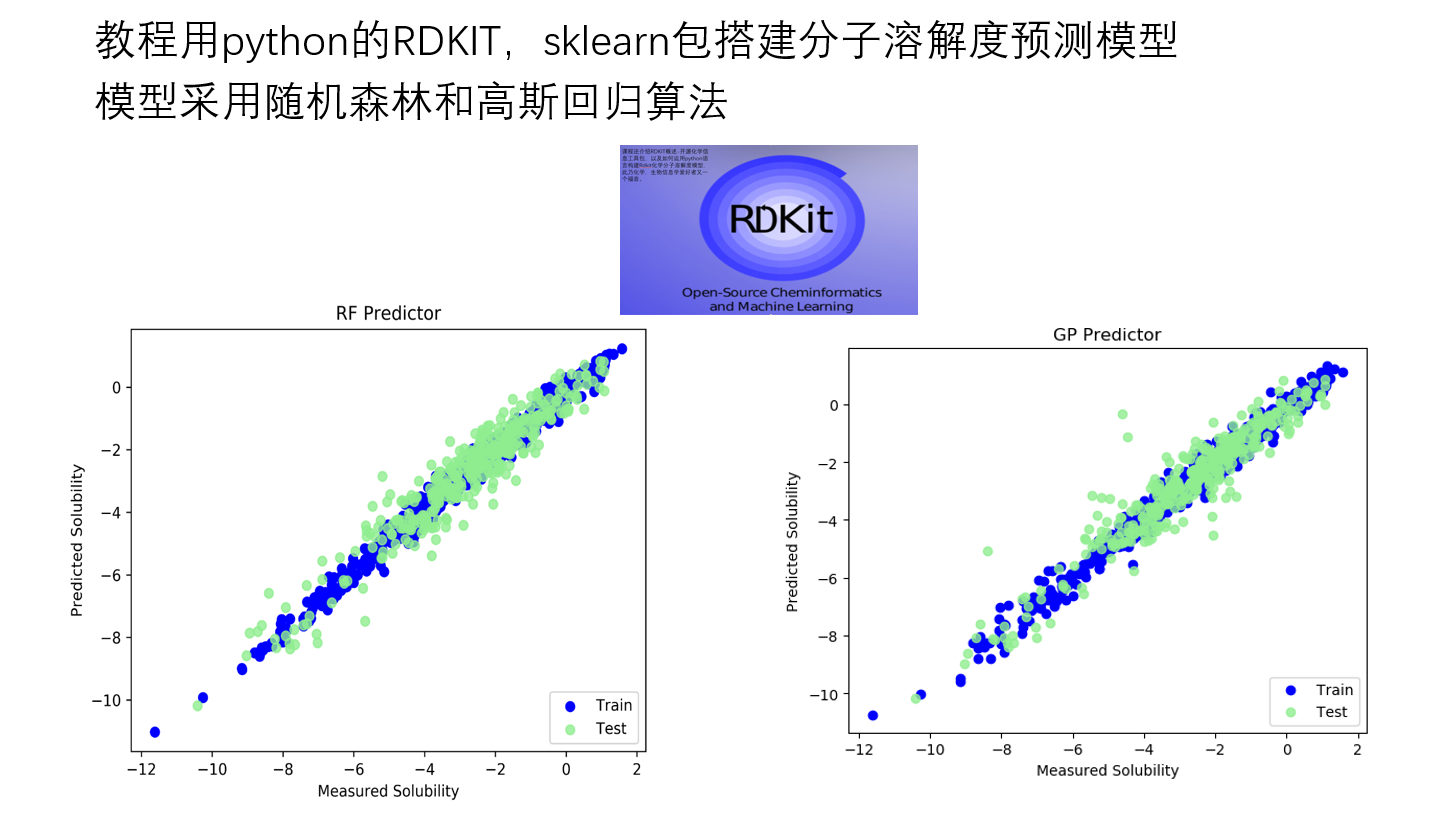
Toby,持牌照金融公司担任模型验证专家,国内最大医药数据中心数据挖掘部门负责人!和重庆儿科医院,中科院教授,赛柏蓝保持慢病数据挖掘项目合作!管理过欧美日中印巴西等国外药典数据库,马丁代尔数据库,FDA溶解度数据库,临床试验数据库,WHO药物预警等数据库。
课程概述
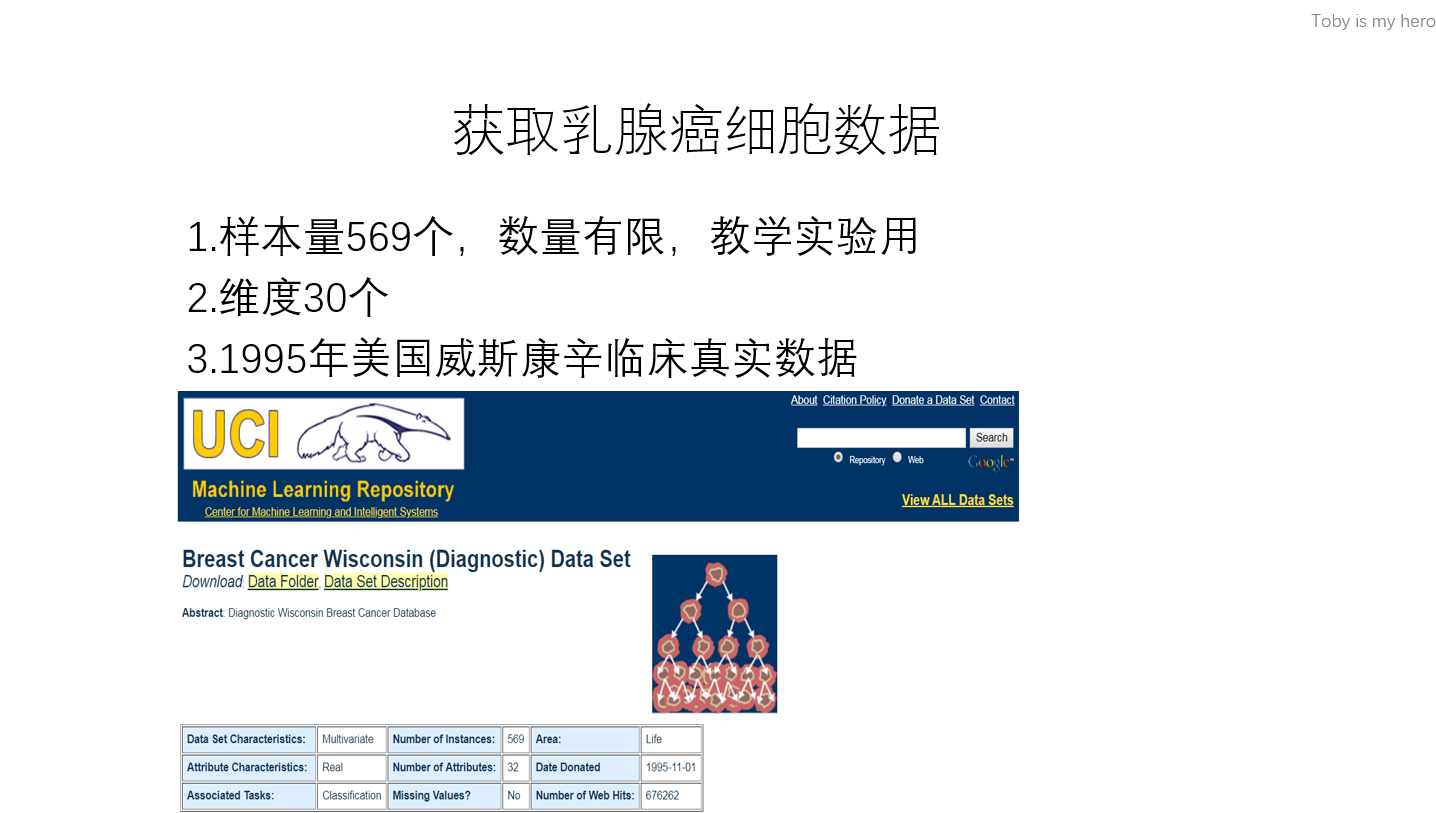
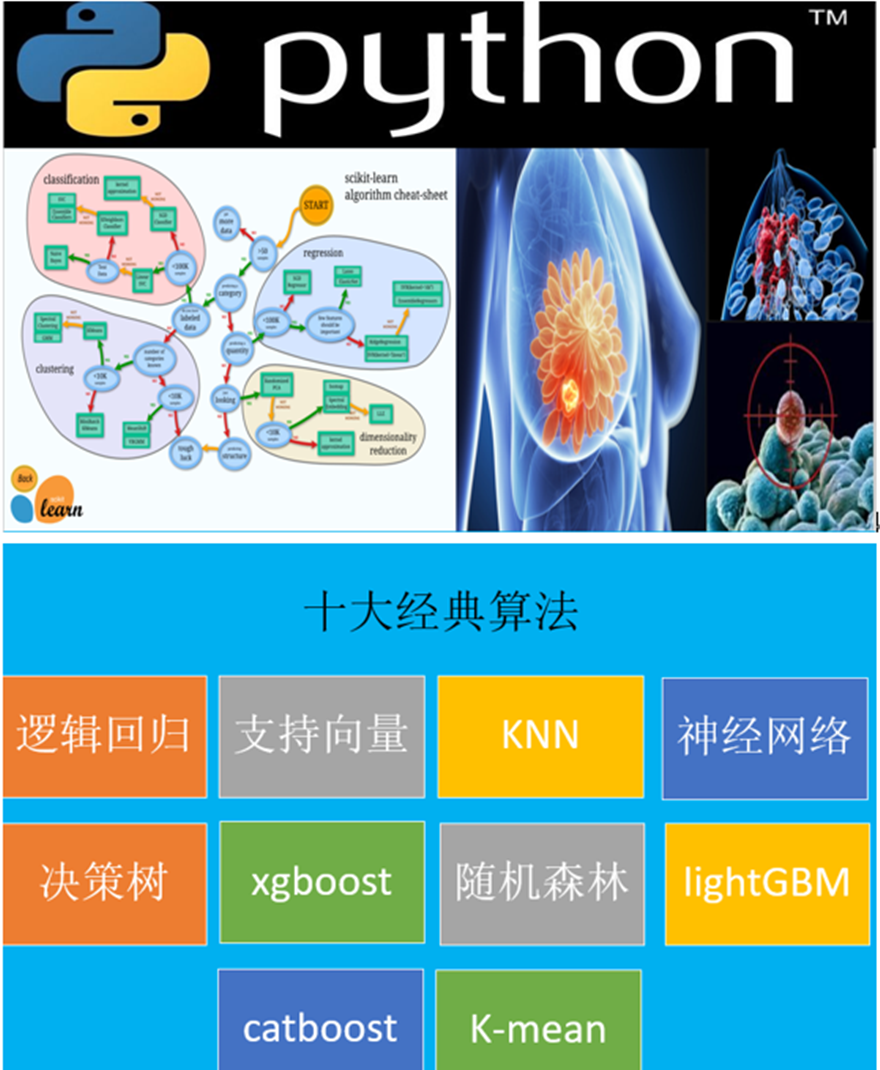
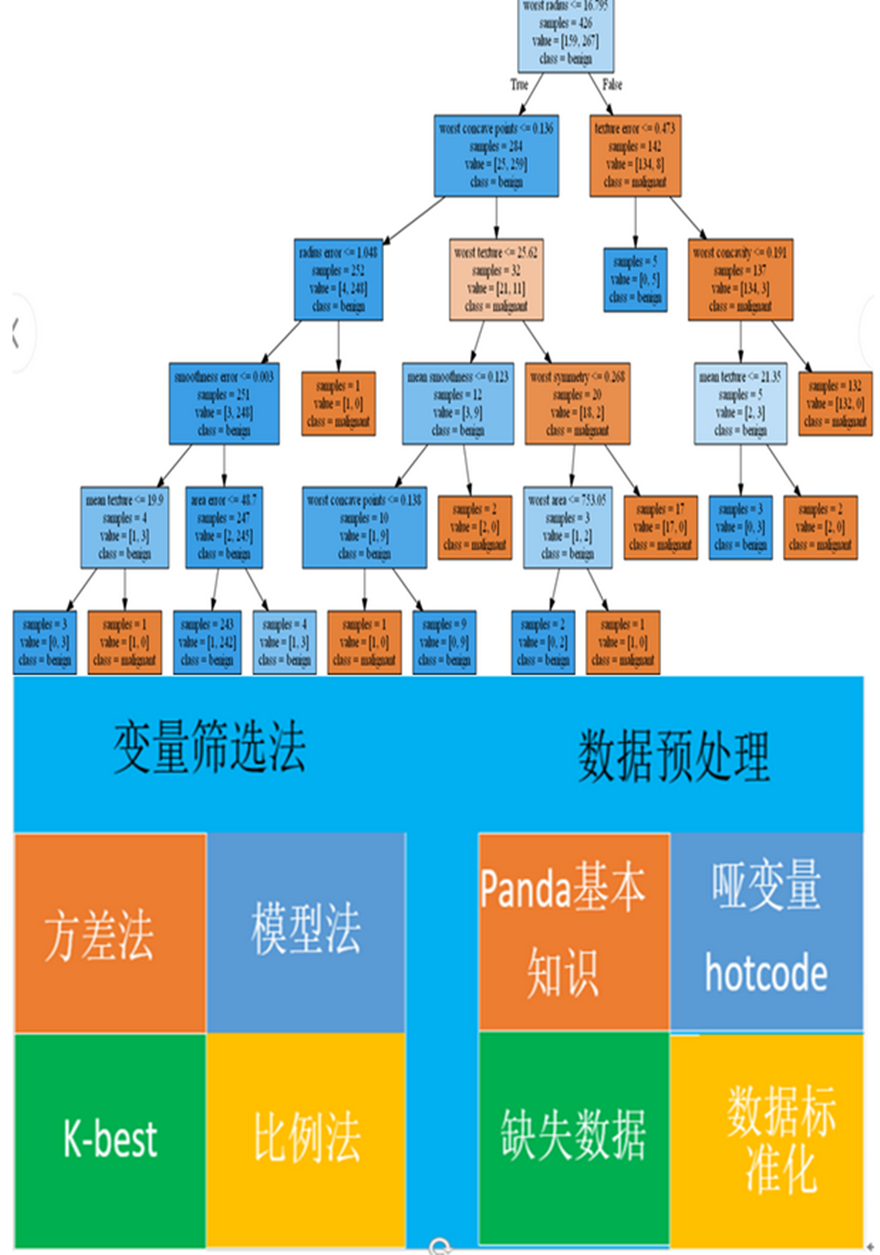
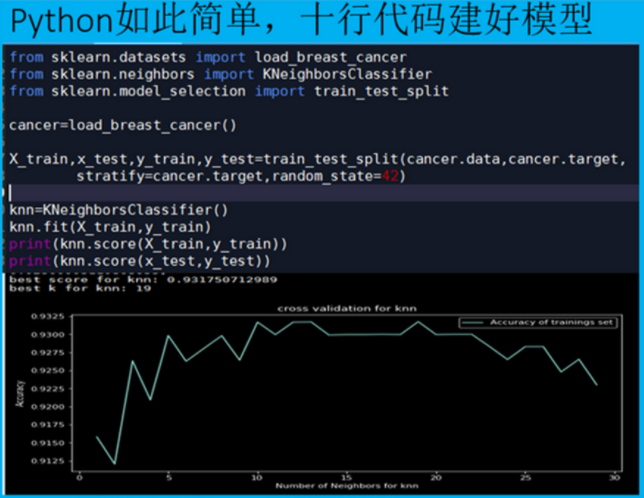
此课程讲述如何运用python的sklearn快速建立机器学习模型。课程结合美国威斯康辛乳腺癌细胞临床数据,实操演练,建立癌细胞预测分类器。
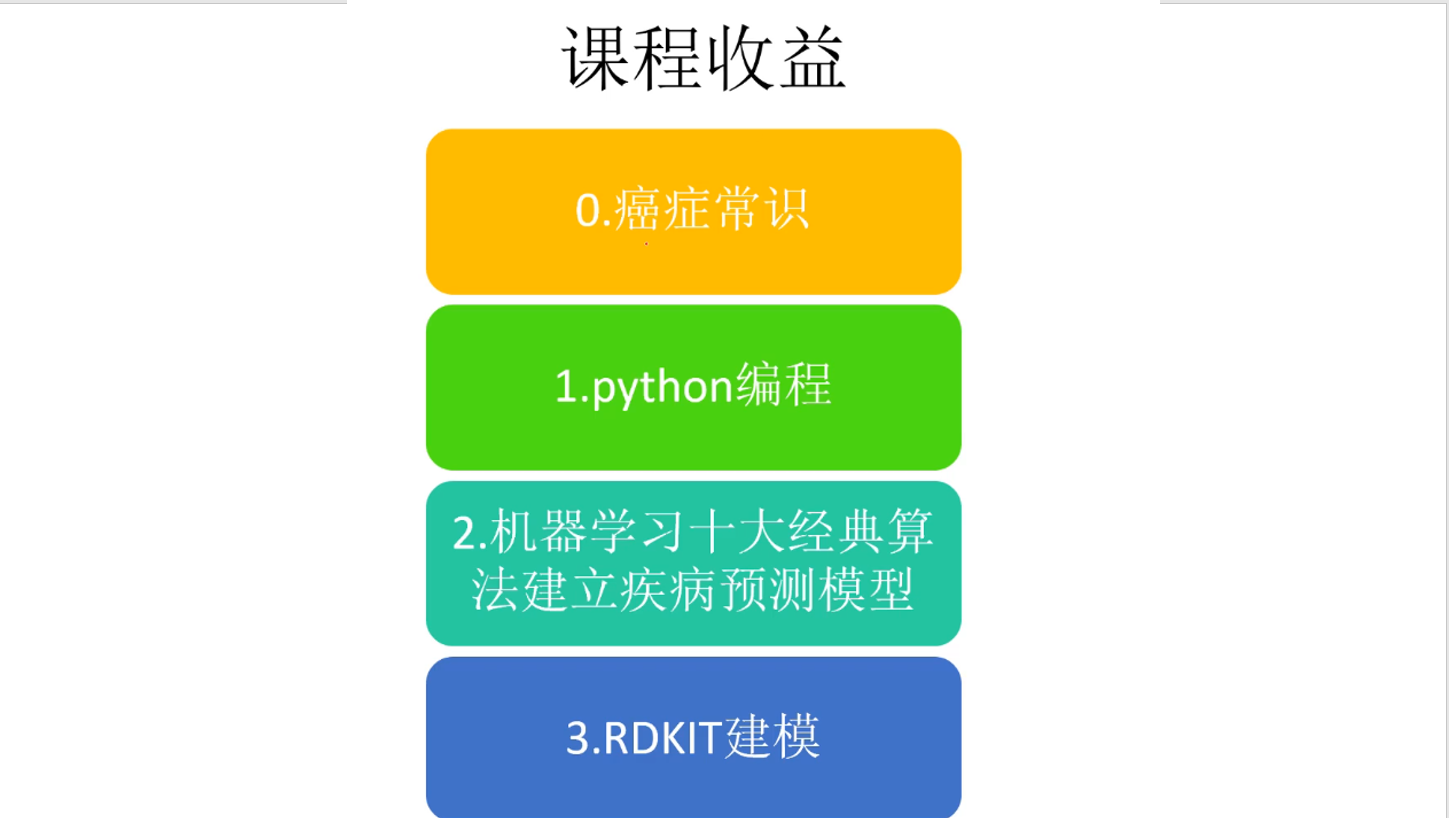
课程讲述十大经典机器学习算法:逻辑回归,支持向量,KNN,神经网络,随机森林,xgboost,lightGBM,catboost。这些算法模型可以应用于各个领域数据。
本视频系列通俗易懂,课程针对学生和科研机构,python爱好者。
本视频教程系列有完整python代码,观众看后可以下载实际操作。
了解癌症肿瘤基本常识,建立健康生活方式,预防癌症,减轻癌症治疗成本。
课程背景
警钟长鸣!癌症离我们远吗?《我不是药神》催人泪下,笔者在此揭露真相,癌症不是小概率疾病,癌症就在身边。癌症早期发现和控制可极大延长寿命和减少治疗费用。笔者下载美国威斯康辛临床数据,运用python sklearn建立乳腺癌分类器模型,可预测正常细胞和癌细胞。我国医院重视治疗,但忽略疾病预防教育。通过我多年机器学习数据挖掘,我发现疾病可防可控,通过自身努力,我们可以提前发现疾病早期症状或扼杀疾病于摇篮。希望此课程让广大医疗科研工作者认识疾病预防教育重要性。




信息系统项目管理师自考笔记
李明 · 992人在学
python从0到1:期货量化交易系统(CTP实战,高频及合成K线数据
王先生 · 23104人在学

手把手搭建Java超市管理系统【附源码】(毕设)
汤小洋 · 4328人在学
Java毕设springboot外卖点餐系统 毕业设计毕设源码 使用教
黄菊华 · 856人在学
基于SSM酒店管理系统(毕设)
小尼老师 · 919人在学
java项目实战之购物商城(java毕业设计)
Long · 5222人在学

手把手搭建Java求职招聘系统【附源码】(毕设)
汤小洋 · 1544人在学
Python Django 深度学习 小程序
钟翔 · 2445人在学

城管局门前三包管理系统+微信小程序(vue+springboot)
赖国荣 · 721人在学
Vue+Uni-app(uniapp)入门与实战+赠送仿美团点餐小程序
李杰 · 4111人在学