30天大数据Hadoop生态圈体系完整教程
Linux第1天
Linux第2天
Zookeeper第1天
Zookeeper第2天
Hadoop第1天
Hadoop第2天
Hadoop第3天
Hadoop第4天
Hadoop第5天
Hadoop第6天
Hadoop第7天
Hadoop第8天
Hadoop第9天
Hadoop第10天
Hive第1天
Hive第2天
Hive第3天
Hive第4天
Avropb
Hbase第1天
Hbase第2天
Hbase第3天
Hbase第4天
Hbase第5天
Phoenix第1天
Phoenix第2天
Redis
- 01.redis简介-windows安装
- 02.redis Linux下编译安装
- 03.常用命令-保护模式-client API访问
- 04.redis hash类型
- 05.redis list类型1
- 05.redis list类型2
- 06.set集合-sorted_set集合1
- 06.set集合-sorted_set集合2
- 07.redis sorted_set-string
- 08.redis事务
- 09.redis发布订阅
- 10.redis中存放图片
- 11.redis watch观测key对事务的干扰
- 12.redis搭建集群
- 13.redis集群client API
- 14.redis集群修改命令-权限问题
Ganglia
Flume第1天
- 01.flume-简介-安装
- 02.使用nc源-内存通道-体验flume日志收集
- 03.常用源-seq-stress-spooldir
- 04.flume-常用源-exec-实时收集
- 05.flume-常用sink-fileRoll
- 06.flume-常用sink-hdfsSink
- 07.常用sink-hiveSink(问题)1
- 07.常用sink-hiveSink(问题)2
- 08.flume-常用sink-hbasesink
- 09.hbasesink-正则字段名称指定
- 10.flume-常用通道-memory-file1
- 10.flume-常用通道-memory-file2
- 11.flume-自定义sink-验证file通道1
- 11.flume-自定义sink-验证file通道2
Flume第2天
Sqoop
Kafka第1天
Kafka第2天
馈,我们将及时处理!
课时介绍
课程介绍
本教程为版权作品,盗版必究
精心规划,课程涵盖Hadoop大数据生态圈全方位剖析,做到知识无死角,挑战高薪大数据职位;
循序渐进,由浅入深学习大数据技能,大数据处理技术方方面面一览无余,积跬步以至千里。企业案例,理论与实际相结合,技术与操作同进行,学以致用,止于至善。
从内到外理解大数据各种技术,Linux、Zookeeper、Hadoop、Hive、Avropb、HBase+Phoenix、Redis、Ganglia、Flume、Sqoop、Kafka等全部技术源码级传授,从无到有掌握Hadoop生态圈技术。

信息系统项目管理师自考笔记
李明 · 1011人在学
python从0到1:期货量化交易系统(CTP实战,高频及合成K线数据
王先生 · 23133人在学

手把手搭建Java超市管理系统【附源码】(毕设)
汤小洋 · 4330人在学
Java毕设springboot外卖点餐系统 毕业设计毕设源码 使用教
黄菊华 · 856人在学
基于SSM酒店管理系统(毕设)
小尼老师 · 923人在学
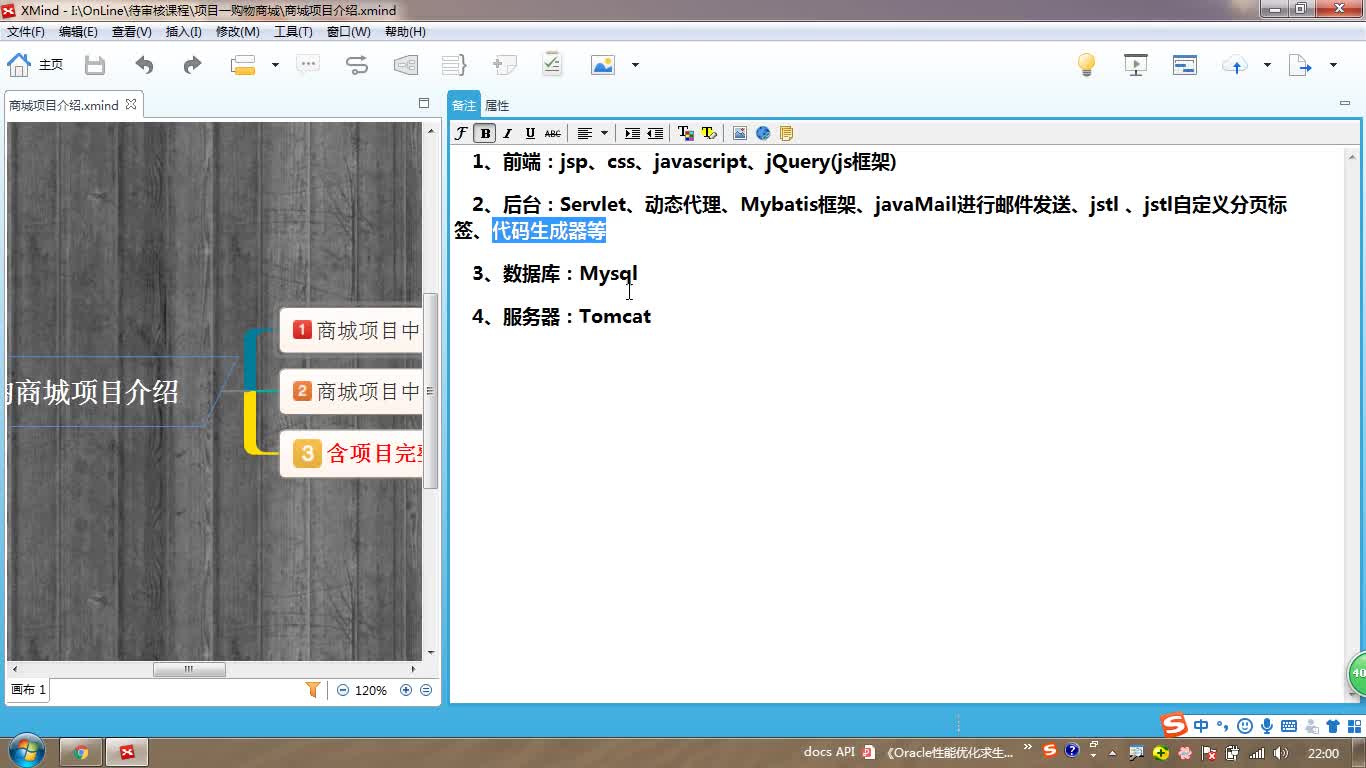
java项目实战之购物商城(java毕业设计)
Long · 5223人在学

手把手搭建Java求职招聘系统【附源码】(毕设)
汤小洋 · 1546人在学
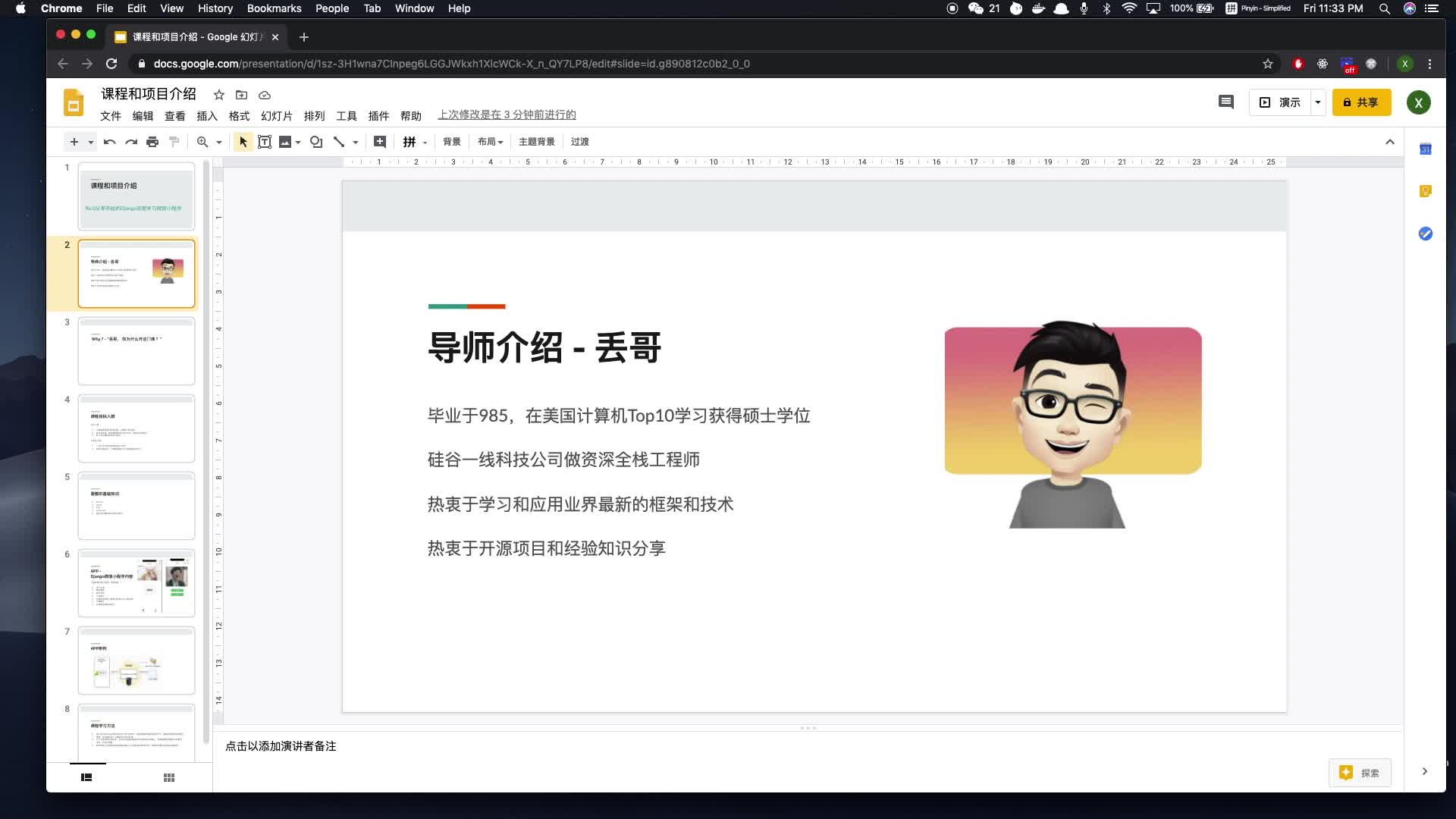
Python Django 深度学习 小程序
钟翔 · 2447人在学

城管局门前三包管理系统+微信小程序(vue+springboot)
赖国荣 · 730人在学
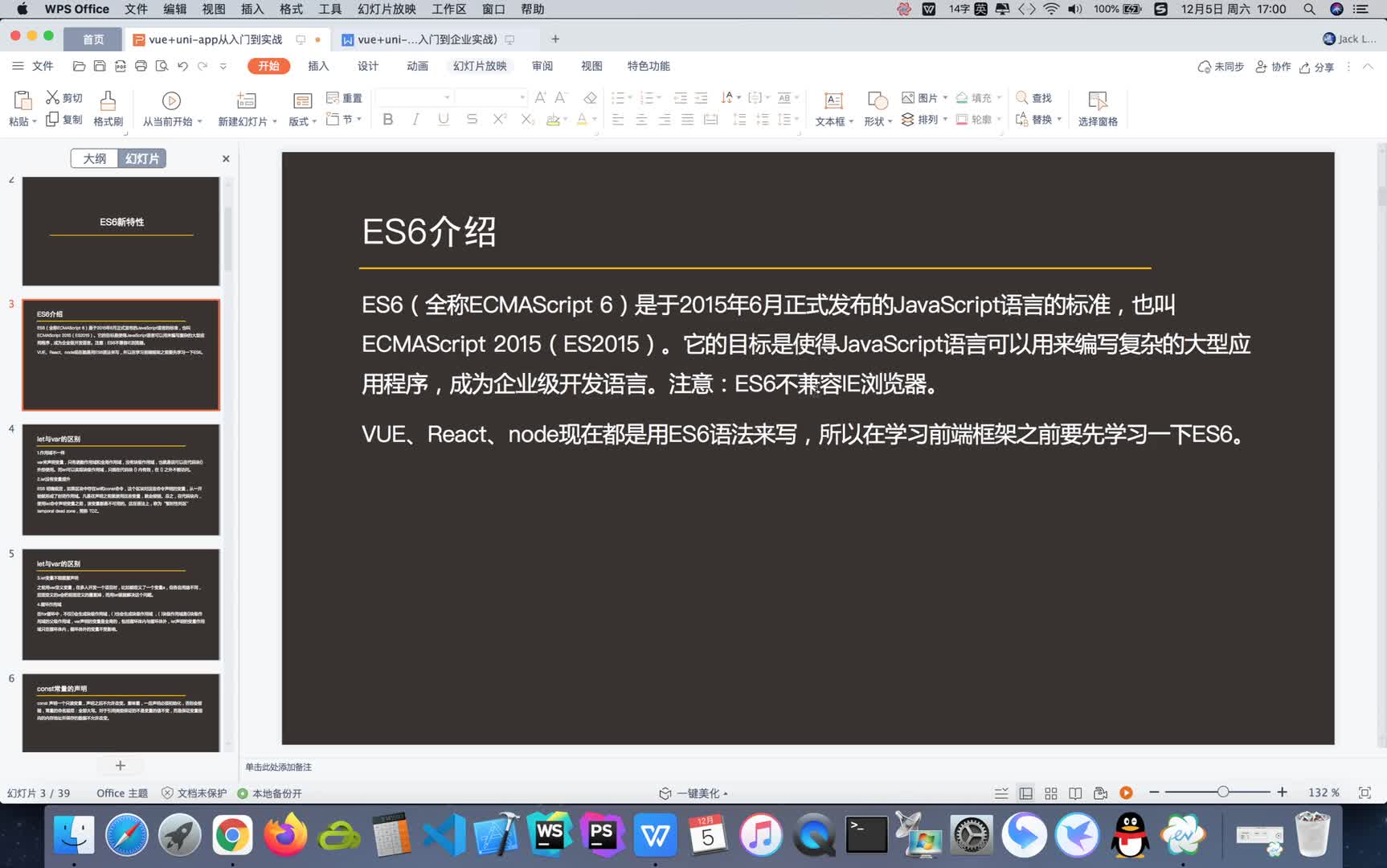
Vue+Uni-app(uniapp)入门与实战+赠送仿美团点餐小程序
李杰 · 4117人在学