大规模数据处理计算引擎Spark2.x教程(含资料)
课时介绍
课程介绍
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)所开源的类Hadoop MapReduce的通用并行框架,Spark,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是——Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
Spark 是一种与 Hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些有用的不同之处使 Spark 在某些工作负载方面表现得更加优越,换句话说,Spark 启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。
Spark 是在 Scala 语言中实现的,它将 Scala 用作其应用程序框架。与 Hadoop 不同,Spark 和 Scala 能够紧密集成,其中的 Scala 可以像操作本地集合对象一样轻松地操作分布式数据集。
尽管创建 Spark 是为了支持分布式数据集上的迭代作业,但是实际上它是对 Hadoop 的补充,可以在 Hadoop 文件系统中并行运行。通过名为 Mesos 的第三方集群框架可以支持此行为。Spark 由加州大学伯克利分校 AMP 实验室 (Algorithms, Machines, and People Lab) 开发,可用来构建大型的、低延迟的数据分析应用程序。
本部分内容全面涵盖了Spark生态系统的概述及其编程模型,深入内核的研究,Spark on Yarn,Spark RDD、Spark Streaming流式计算原理与实践,Spark SQL,Spark的多语言编程以及SparkR的原理和运行。本套Spark教程不仅面向项目开发人员,甚至对于研究Spark的在校学员,都是非常值得学习的。

信息系统项目管理师自考笔记
李明 · 973人在学
python从0到1:期货量化交易系统(CTP实战,高频及合成K线数据
王先生 · 23019人在学

手把手搭建Java超市管理系统【附源码】(毕设)
汤小洋 · 4318人在学
Java毕设springboot外卖点餐系统 毕业设计毕设源码 使用教
黄菊华 · 847人在学
基于SSM酒店管理系统(毕设)
小尼老师 · 909人在学
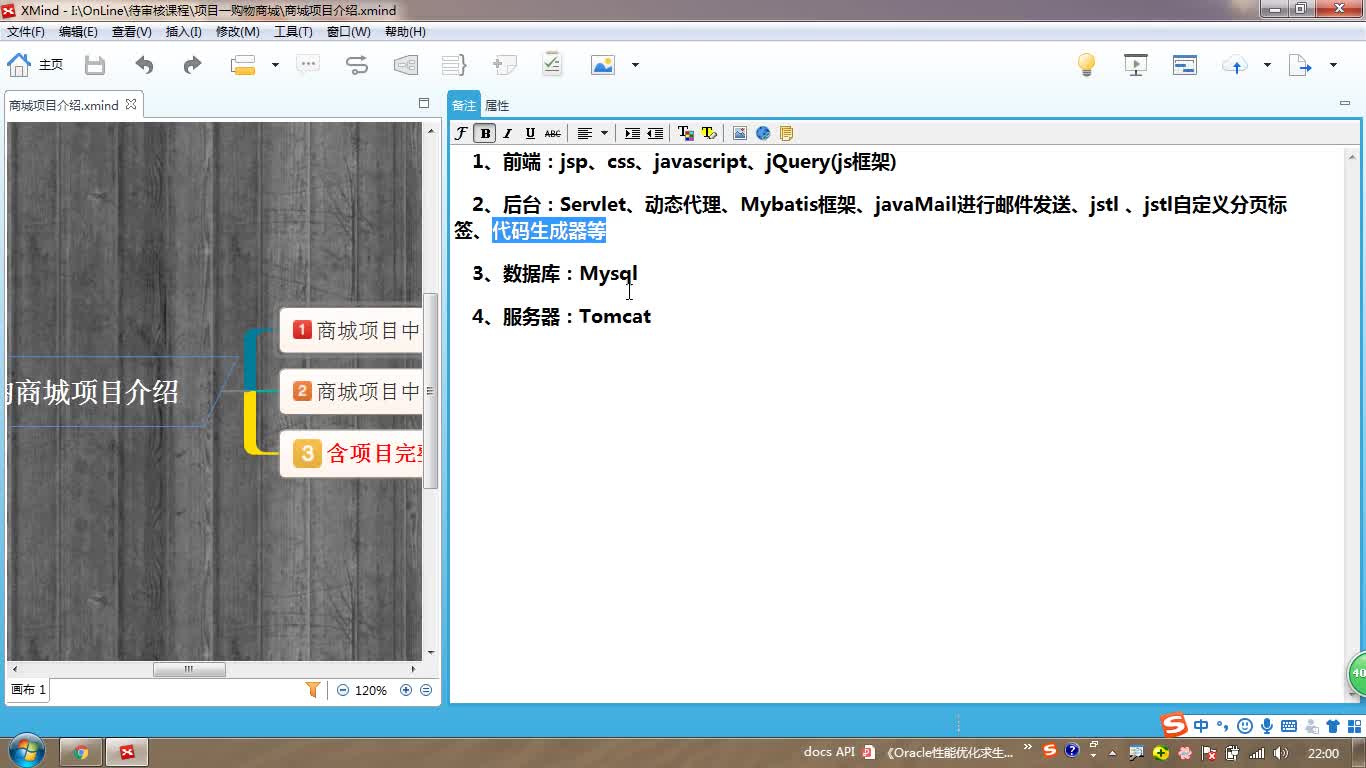
java项目实战之购物商城(java毕业设计)
Long · 5217人在学

手把手搭建Java求职招聘系统【附源码】(毕设)
汤小洋 · 1541人在学
Python Django 深度学习 小程序
钟翔 · 2436人在学

城管局门前三包管理系统+微信小程序(vue+springboot)
赖国荣 · 711人在学
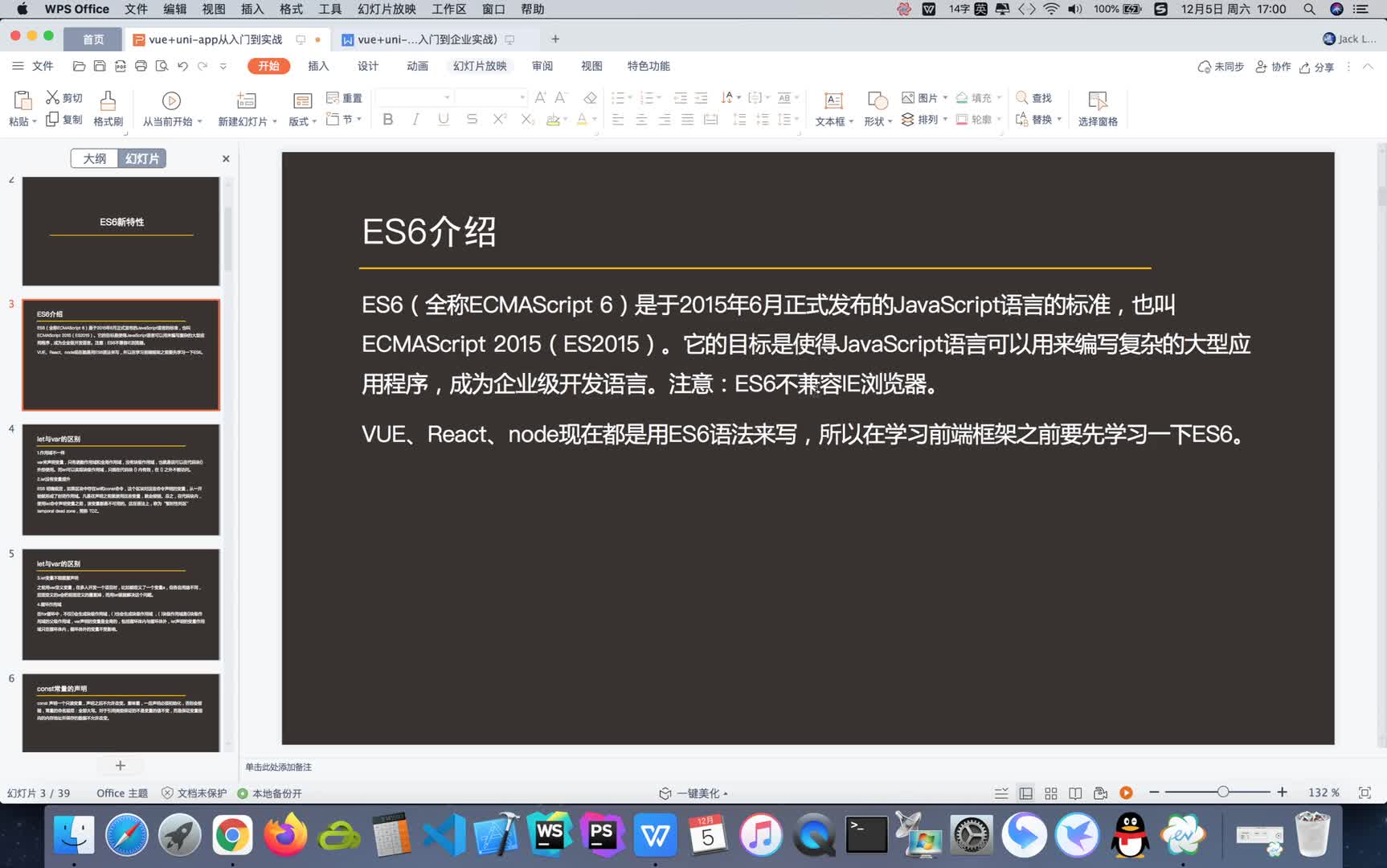
Vue+Uni-app(uniapp)入门与实战+赠送仿美团点餐小程序
李杰 · 4103人在学