大数据技术
大数据技术之Linux
- 01-大数据Linux-基本介绍
- 02-大数据Linux-发展历程
- 03-大数据Linux-和Unix关系
- 04-大数据Linux-安装VM
- 05-大数据Linux-安装Centos的准备工作
- 06-大数据Linux-安装Centos的步骤
- 07-大数据Linux-Centos终端和联网的说明
- 08-大数据Linux_文件系统目录结构
- 09-大数据Linux-远程登录XShell5
- 10-大数据Linux-远程传输文件XFTP5
- 11-大数据Linux-SecureCRT安装使用
- 12-大数据Linux-Vi和Vim的使用
- 13-大数据Linux-关机重启注销
- 14-大数据Linux-用户管理 创建用户指定密码
- 15-大数据Linux-用户管理 删除用户
- 16-大数据Linux-用户管理 查询切换用户
- 17-大数据Linux-用户管理 组的管理
- 18-大数据Linux-用户管理 用户和组的配置文件
- 19-大数据Linux-实用指令 运行级别和找回root密码
- 20-大数据Linux-实用指令 帮助指令
- 21-大数据Linux-实用指令 pwd ls cd
- 22-大数据Linux-实用指令 mkdir rmdir
- 23-大数据Linux-实用指令 touch cp
- 24-大数据Linux-实用指令 rm mv
- 25-大数据Linux-实用指令 cat more less
- 26-大数据Linux-实用指令 重定向和追加
- 27-大数据Linux-实用指令 echo head tail
- 28-大数据Linux-实用指令 ln history
- 29-大数据Linux-实用指令 date cal
- 30-大数据Linux-实用指令 find locate grep 管道符
- 31-大数据Linux-实用指令 压缩和解压类指令
- 32-大数据Linux-组管理
- 33-大数据Linux-权限详细介绍
- 34-大数据Linux-权限管理
- 35-大数据Linux-权限最佳实践
- 36-大数据Linux-任务调度基本说明
- 37-大数据Linux-任务调度应用实例
- 38-大数据Linux-磁盘分区介绍
- 39-大数据Linux-分区
- 40-大数据Linux-给Linux添加一块新硬盘
- 41-大数据Linux-磁盘查询实用指令
- 42-大数据Linux-网络配置原理和说明
- 43-大数据Linux-自动获取IP
- 44-大数据Linux-修改配置文件指定IP
- 45-大数据Linux-修改Linux主机名
- 46-大数据Linux-进程介绍和查询
- 47-大数据Linux-进程管理 终止进程
- 48-大数据Linux-进程管理 服务管理
- 49-大数据Linux-进程管理 监控服务
- 50-大数据Linux-RPM包管理
- 51-大数据Linux-YUM
- 52-大数据Linux-企业真实面试题
- 53-大数据Linux-结束语-程序人生感悟
大数据技术之Shell
- Shell课程介绍
- Shell概述
- Shell解析器
- ShellHelloWorld案例
- Shell多命令操作案例
- Shell系统变量和自定义变量案例
- Shell$n案例
- Shell$#案例
- Shell$※$@案例
- Shell$?案例
- Shell运算符
- Shell条件判断案例
- Shell回顾
- Shellif案例
- ShellCase案例
- ShellFor1案例
- ShellFor2案例
- ShellWhile案例
- ShellRead案例
- ShellBaseName&DirName案例
- Shell自定义函数案例
- ShellCut案例
- ShellSed案例
- ShellAwk案例
- ShellSort案例
- Shell企业真题讲解
大数据技术之Hadoop
- 课程简介大数据课程
- 课程简介Hadoop课程
- 入门大数据概念
- 入门大数据特点(4V)
- 入门大数据应用场景
- 入门大数据发展前景
- 入门大数据部门业务流程分析
- 入门大数据部门组织结构(重点)
- Hadoop是什么
- Hadoop发展历史
- Hadoop三大发行版本
- Hadoop优势(4高)
- Hadoop1-x和2-x区别
- Hadoop组成
- Hadoop大数据技术生态体系
- Hadoop推荐系统框架图
- 环境搭建虚拟机准备
- 环境搭建JDK安装
- 环境搭建Hadoop安装
- 环境搭建Hadoop目录结构
- 环境搭建Hadoop官网手册
- 本地模式Grep官方案例
- 本地模式WordCount官方案例
- 伪分布式启动HDFS并运行MR程序
- 伪分布式Log日志查看和NN格式化前强调
- 伪分布式NameNode格式化注意事项
- 伪分布式启动YARN并运行MR程序
- 伪分布式配置历史服务器
- 伪分布式配置日志聚集
- 伪分布式配置文件说明
- 完全分布式虚拟机环境准备
- 完全分布式scp案例
- 完全分布式rsync案例
- 完全分布式集群分发脚本xsync
- 完全分布式集群配置
- 完全分布式集群单节点启动
- 完全分布式集群ssh配置
- 完全分布式集群群起
- 完全分布式集群文件存储路径说明
- 完全分布式集群启动停止方式总结
- 每日回顾
- 完全分布式RM启动注意事项
- 完全分布式Crondtab定时任务调度
- 完全分布式集群时间同步
- Hadoop源码编译意义
- Hadoop源码编译说明
- Hadoop源码编译具体流程
- HDFS课程介绍
- HDFS产生背景及定义
- HDFS优缺点
- HDFS组成架构
- HDFS块的大小设置
- HDFSShell命令(开发重点)
- HDFS副本数设置
- HDFS客户端环境准备
- HDFS客户端环境测试
- 每日回顾
- 文件上传案例
- 参数优先级说明案例
- 文件下载案例
- 文件夹删除案例
- 修改文件的名称案例
- 查看文件的详情案例
- 判断是文件还是文件夹案例
- 文件IO流上传案例
- 文件IO流下载操作案例
- 定位读取文件案例
- HDFS写数据流程(面试重点)
- HDFS网络拓扑-节点距离计算
- HDFS机架感知-副本存储节点选择
- HDFS读数据流程(面试重点)
- HDFSNN和2NN工作机制(面试重点)
- HDFSFsimage和Edits解析
- HDFSCheckPoint时间设置
- NN故障处理案例
- HDFS安全模式
- 集群安全模式案例
- NN多目录配置案例
- 每日回顾
- HDFSDN工作机制(面试重点)
- HDFS数据完整性
- HDFS掉线时限参数设置
- 服役新节点案例
- 添加白名单案例
- 黑名单退役案例
- DN多目录配置案例
- HDFS新特性集群间数据拷贝
- HDFS新特性小文件归档案例
- HDFS新特性回收站案例
- HDFS新特性快照管理
- MapReduce课程介绍
- MapReduce概述
- MapReduce优缺点
- MapReduce核心思想
- MapReduce进程
- MapReduce官方案例源码解析和数据类型
- MapReduce编程规范
- MapReduceWordCount案例分析
- MapReduceWordCount案例Mapper
- MapReduceWordCount案例Reducer
- MapReduceWordCount案例Driver
- MapReduceWordCount案例测试
- MapReduceWordCount案例Debug调试
- MapReduceWordCount案例在集群上运行
- 每日回顾
- MapReduce序列化概述
- MapReduce序列化自定义步骤
- MapReduce序列化案例分析
- MapReduce序列化案例FlowBean
- MapReduce序列化案例Mapper
- MapReduce序列化案例Reducer
- MapReduce序列化案例Driver
- MapReduce序列化案例Debug调试
- MapReduce切片和MapTask并行度决定机制
- MapReduceJob提交流程源码解析
- MapReduceJob切片机制源码解析
- MapReduceFileInputFormat切片机制和配置参数
- MapReduceCombineTextInputFormat理论
- MapReduceCombineTextInputFormat案例
- MapReduceFileInputFormat实现类
- MapReduceTextInputFormat实现类
- 每日回顾
- MapReduceKeyValueTextInputFormat案例分析
- MapReduceKeyValueTextInputFormat案例实现
- MapReduceNLineInputFormat案例分析
- MapReduceNLineInputFormat案例实现
- MapReduce自定义InputFormat步骤
- MapReduce自定义InputFormat案例
- MapReduce自定义InputFormat案例Debug
- MapReduceInputFormat实现类总结
- MapReduce工作流程(面试重点)
- MapReduceShuffle机制(面试重点)
- MapReduceHashPartition默认分区
- MapReducePartition分区案例
- MapReducePartition分区案例总结
- 每日回顾
- MapReduce回顾分区
- MapReduce排序概述
- MapReduce排序分类
- MapReduce全排序案例分析
- MapReduce全排序案例FlowBean
- MapReduce全排序案例Mapper
- 全排序案例Mapper已处理
- MapReduce全排序案例实现及测试
- MapReduce分区排序案例实现及测试
- MapReduceDebug调试思想
- MapReduceCombiner理论
- MapReduceCombiner案例实现
- MapReduce分组排序案例分析
- MapReduce分组排序案例OrderBean
- MapReduce分组排序案例Mapper
- MapReduce分组排序案例Driver
- MapReduce分组排序案例排序类
- MapReduce分组排序案例调试
- MapReduce分组排序案例扩展
- MapReduceMapTask工作机制(面试重点)
- MapReduceReduceTask工作机制(面试重点)
- MapReduceReduceTask个数设置
- MapReduceShuffle机制(面试重点)
- MapReduce工作流程源码分析
- MapReduceOutPutFormat接口实现类
- MapReduce自定义OutputFormat案例分析
- MapReduce自定义OutputFormat案例实现
- MapReduceReduceJoin理论
- MapReduceReduceJoin案例分析
- MapReduceReduceJoin案例TableBean
- MapReduceReduceJoin案例Mapper
- MapReduceReduceJoin案例Reduce
- MapReduceReduceJoin案例Driver
- MapReduceReduceJoin案例Debug和总结
- MapReduceMapJoin案例分析
- MapReduceMapJoin案例缓存文件处理
- MapReduceMapJoin案例测试
- MapReduce计数器应用
- MapReduce数据清洗案例
- MapReduce开发总结
- 压缩概述
- 压缩MR支持的压缩编码
- 压缩方式选择
- 压缩位置选择
- 压缩参数设置
- 压缩压缩案例
- 压缩解压缩案例
- 压缩Map和Reduce启用压缩案例
- YARN基本架构
- YARN工作机制
- YARN作业提交全流程
- YARN资源调度器
- YARN任务推测执行
- 企业调优MR跑的慢的原因
- 企业调优MR优化方法
- 企业调优HDFS小文件处理
- 扩展案例多Job串联案例分析
- 扩展案例多Job串联案例第一个Job
- 扩展案例多Job串联案例完成
- 扩展案例TopN案例
- 扩展案例找共同粉丝(学生版1)
- 扩展案例找共同粉丝(学生版2)
- Hadoop总结企业真实面试题讲解
- Hadoop总结开发重点
大数据技术之Zookeeper
- Zookeeper课程介绍
- Zookeeper概述
- Zookeeper特点
- Zookeeper数据结构
- Zookeeper应用场景
- Zookeeper下载地址
- Zookeeper本地模式安装
- Zookeeper配置参数解读
- Zookeeper选举机制
- Zookeeper节点类型
- Zookeeper分布式安装
- ZookeeperShell命令操作
- ZookeeperStat结构体
- Zookeeper监听器原理
- Zookeeper写数据流程
- Zookeeper创建ZooKeeper客户端
- Zookeeper创建一个节点
- Zookeeper获取子节点并监听节点变化
- Zookeeper判断节点是否存在
- Zookeeper服务器节点动态上下线案例分析
- Zookeeper服务器节点动态上下线案例注册代码
- Zookeeper服务器节点动态上下线案例全部代码实现
- Zookeeper企业面试真题
大数据技术之HadoopHA
大数据技术之Hive
- Hive入门课程介绍
- Hive入门是什么
- Hive入门优缺点
- Hive入门架构
- Hive入门与数据库比较
- Hive安装安装与配置
- Hive安装启动
- Hive安装加载本地数据到Hive表
- Hive安装MySQL服务
- Hive安装配置MySQL无主机登录
- Hive安装配置MetaStore到MySQL
- Hive安装中常用的交互命令
- Hive安装其他操作命令
- Hive安装常见属性配置
- Hive安装参数配置方式
- Hive安装基本数据类型
- Hive安装复杂数据类型
- Hive安装类型转化
- Hive数据定义创建数据库
- Hive数据定义数据库查询
- Hive数据定义数据库修改
- Hive数据定义数据库删除
- Hive数据定义创建表的语法
- Hive数据定义回顾
- Hive数据定义HiveServer2
- Hive数据定义内部表
- Hive数据定义外部表
- Hive数据定义内外部表转换
- Hive数据定义分区表基本操作
- Hive数据定义二级分区
- Hive数据定义分区表与数据关联的三种方式
- Hive数据定义修改表
- Hive数据操作Load方式加载数据
- Hive数据操作Insert方式加载数据
- Hive数据操作Location方式加载数据
- Hive数据操作Import方式导入数据失败
- Hive数据操作Insert导出数据
- Hive数据操作导出数据的其他方式&Import导入数据成功
- Hive数据操作清空表数据
- Hive数据操作元数据信息
- Hive查询基本查询
- Hive查询常用的基本函数
- Hive查询Where子句查询
- Hive查询逻辑运算符
- Hive查询GroupBy & Having
- Hive查询Join操作
- Hive查询回顾(一)
- Hive查询回顾(二)
- Hive排序OrderBy
- Hive排序SortBy
- Hive排序DistributeBy
- Hive排序ClusterBy
- Hive排序总结
- Hive分桶表创建
- Hive分桶抽样查询
- Hive高级给NULL赋值
- Hive高级CaseWhen
- Hive高级行转列
- Hive高级列转行
- Hive高级窗口函数需求(一)
- Hive高级窗口函数需求(二)
- Hive高级窗口函数需求(三)
- Hive高级窗口函数需求(四)
- Hive高级窗口函数需求(五)
- Hive高级回顾
- Hive高级窗口函数回顾
- Hive高级Rank
- Hive高级函数介绍
- Hive高级自定义函数
- Hive高级压缩
- Hive高级存储格式介绍
- Hive高级存储格式比较
- Hive高级存储与压缩结合
- Hive优化Fetch抓取
- Hive优化本地模式
- Hive优化小表Join大表
- Hive优化空key处理
- Hive优化MapJoin
- Hive优化GroupBy
- Hive优化去重统计
- Hive优化行列过滤
- Hive优化动态分区
- Hive优化回顾
- Hive优化数据倾斜
- Hive优化并行执行
- Hive优化严格模式
- Hive优化JVM重用
- Hive优化推测执行&压缩
- Hive优化Explain
- 谷粒影音需求分析
- 谷粒影音Mapper
- 谷粒影音ETLUtil
- 谷粒影音Driver
- 谷粒影音清洗数据
- 谷粒影音建表&导入数据
- 谷粒影音需求(一)
- 谷粒影音需求(二)
- 谷粒影音需求(三)
- 谷粒影音需求(四)
- 谷粒影音需求(五)
- 谷粒影音需求(六)
- 谷粒影音需求(七)
- Hive总结
大数据技术之Flume
- Flume课程介绍
- Flume定义
- Flume组成
- Flume拓扑结构
- FlumeAgent内部原理
- Flume快速入门
- Flume监控端口数据官方案例分析
- Flume监控端口数据官方案例实现
- Flume实时读取本地文件到HDFS案例分析
- Flume实时读取本地文件到HDFS案例实现
- Flume实时读取目录文件到HDFS案例分析
- Flume实时读取目录文件到HDFS案例实现
- Flume单数据源多出口案例(一)分析
- Flume单数据源多出口案例(一)实现
- Flume单数据源多出口案例(Sink组)分析
- Flume单数据源多出口案例(Sink组)实现
- Flume多数据源汇总案例分析
- Flume多数据源汇总案例实现
- Flume监控之Ganglia
- Flume企业面试题讲解
大数据技术之Kafka
- Kafka课程介绍
- Kafka消息队列介绍
- Kafka概念
- Kafka架构
- Kafka集群搭建&启动
- Kafka命令行操作
- Kafka工作流程分析
- Kafka生产数据流程
- Kafka保存数据
- Kafka消费数据
- Kafka回顾
- Kafka生产者API使用
- Kafka带回调函数的生产者
- Kafka自定义分区的生产者
- Kafka高级消费者
- Kafka低级消费者API思路梳理
- Kafka低级API参数设置
- Kafka低级API之获取分区leader
- Kafka低级API之获取分区数据
- Kafka低级API之测试
- Kafka扩展
- Kafka拦截器
- KafkaKafkaStream
- Kafka与Flume对比及集成
大数据技术之Hbase
- HBase课程介绍
- HBase介绍
- HBase特点
- HBase架构
- HBase角色介绍
- HBase安装配置&启动
- HBaseShell操作之增&查
- HBaseShell操作(二)
- HBase删除操作执行
- HBase数据结构
- HBase读数据流程
- HBase写流程
- HBase数据Flush&Compact参数
- HBase回顾
- HBase判断表是否存在旧API
- HBase判断表是否存在新API
- HBase创建表
- HBase删除表
- HBase添加数据
- HBase删除数据
- HBase全表扫描
- HBase获取指定列族:列的数据
- HBase&MR集成官方案例
- HBase自定义MR1之Mapper
- HBase自定义MR1之Reducer&Driver
- HBase自定义MR1打包测试
- HBase自定义MR2完成
- HBase回顾
- HBaseHive与HBase对比
- HBaseHive&HBase集成(需求一)
- HBase向关联表添加数据
- HBaseHive&HBase集成(需求二)
- HBase高可用
- HBase预分区
- HBaseRowKey设计
- HBase内存&基础优化
- HBase谷粒微博之需求分析
- HBase谷粒微博之项目构建
- HBase谷粒微博之创建命名空间
- HBase谷粒微博之创建表
- HBase谷粒微博之发布微博
- HBase谷粒微博之关注用户(一)
- HBase谷粒微博之关注用户(二)
- HBase谷粒微博之关注用户版本问题修复
- HBase回顾(一)
- HBase谷粒微博回顾
- HBase谷粒微博之取关用户
- HBase谷粒微博之获取微博内容&过滤器介绍
- HBase谷粒微博之初始化页面微博内容
- HBase谷粒微博之测试
大数据技术之Sqoop
大数据技术之Oozie

馈,我们将及时处理!
课时介绍
课程介绍
本阶段详细介绍了大数据所涉及到的Linux、shell、Hadoop、zookeeper、HadoopHA、Hive、Flume、Kafka、Hbase、Sqoop、Oozie等技术的概念、安装配置、架构原理、数据类型定义、数据操作、存储集群等重点知识点。

信息系统项目管理师自考笔记
李明 · 990人在学
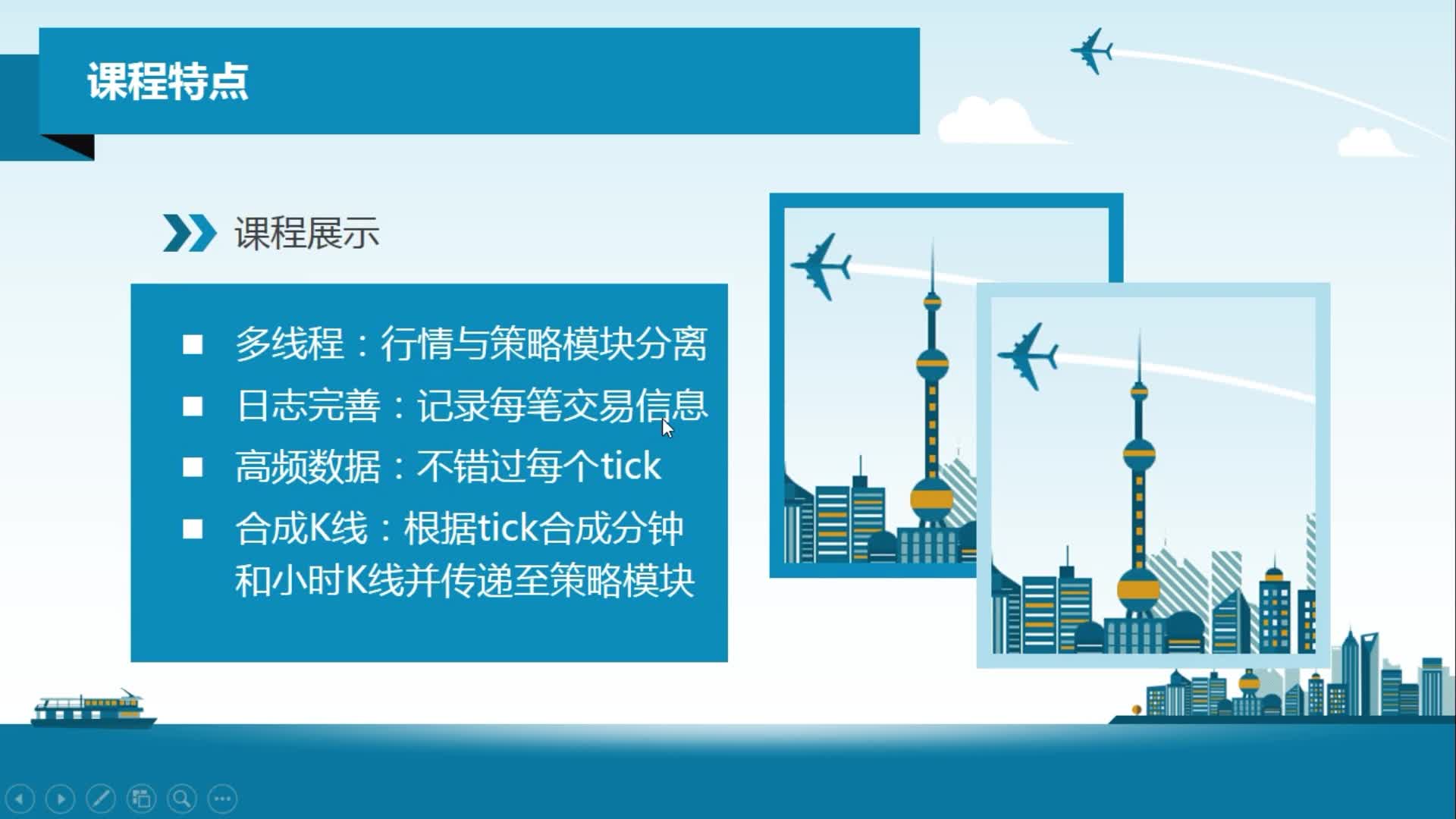
python从0到1:期货量化交易系统(CTP实战,高频及合成K线数据
王先生 · 23099人在学

手把手搭建Java超市管理系统【附源码】(毕设)
汤小洋 · 4328人在学
Java毕设springboot外卖点餐系统 毕业设计毕设源码 使用教
黄菊华 · 855人在学
基于SSM酒店管理系统(毕设)
小尼老师 · 918人在学
java项目实战之购物商城(java毕业设计)
Long · 5222人在学

手把手搭建Java求职招聘系统【附源码】(毕设)
汤小洋 · 1544人在学
Python Django 深度学习 小程序
钟翔 · 2445人在学

城管局门前三包管理系统+微信小程序(vue+springboot)
赖国荣 · 720人在学
Vue+Uni-app(uniapp)入门与实战+赠送仿美团点餐小程序
李杰 · 4111人在学