手把手带你入门深度学习之150行代码的汉字识别系统
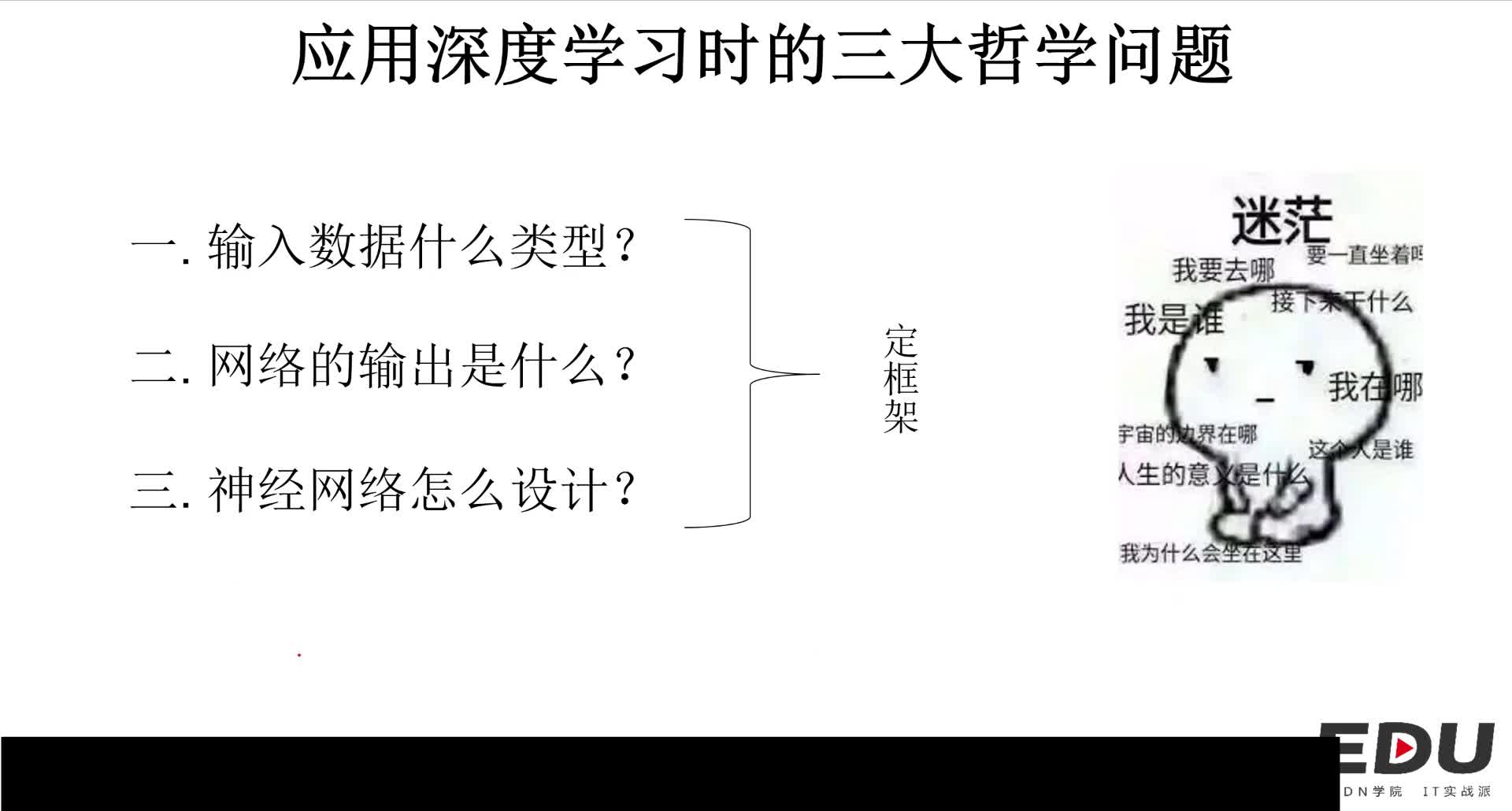
课时介绍
介绍如何用virtualenv在linux系统下构建和管理深度学习环境
课程介绍
在这个课程里面,讲师将会带着同学们一行一行地写代码,同时也对每一行代码它的作用和目的进行讲解,以及在代码调试过程中遇到问题该怎么处理。其次,这个课程不会涉及太多原理性和数学的东西,而是把深度学习看成是一个工具去教会同学们怎么使用,非常适合刚开始接触深度学习和神经网络但不知道该如何下手的同学。最后,这个课程能教会大家一种实际项目的开发思维,适合想要使用深度学习来开发项目的同学。
推荐课程

信息系统项目管理师自考笔记
李明 · 394人在学
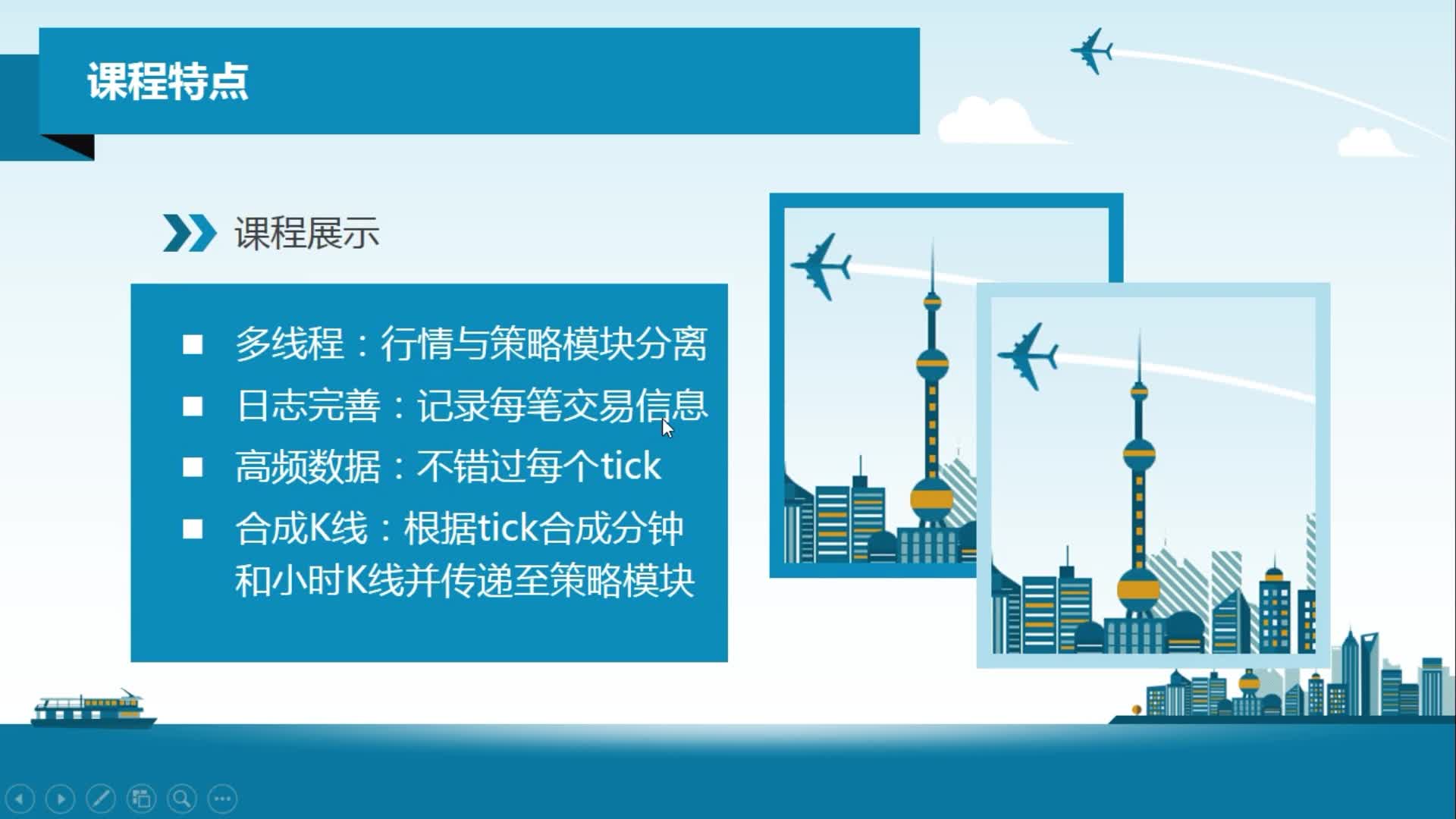
python从0到1:期货量化交易系统(CTP实战,高频及合成K线数据
王先生 · 17748人在学

手把手搭建Java超市管理系统【附源码】(毕设)
汤小洋 · 3767人在学
Java毕设springboot外卖点餐系统 毕业设计毕设源码 使用教
黄菊华 · 669人在学
基于SSM酒店管理系统(毕设)
小尼老师 · 695人在学
java项目实战之购物商城(java毕业设计)
Long · 4936人在学

手把手搭建Java求职招聘系统【附源码】(毕设)
汤小洋 · 1378人在学
Python Django 深度学习 小程序
钟翔 · 2118人在学

城管局门前三包管理系统+微信小程序(vue+springboot)
赖国荣 · 400人在学
Vue+Uni-app(uniapp)入门与实战+赠送仿美团点餐小程序
李杰 · 3554人在学