随着各类文档的爆炸性增长,文档智能领域的研究蓬勃发展。其中,表格是各类文档中常见的页面元素,如何高效地从文档中找到表格并获取内容与结构信息即表格识别,是文档智能的一个重要领域。
本课程就是讲述文档智能领域的一个分支:表格结构化识别。这里不得不说的是目前一个非常流行的开源项目PaddleOCR(Star达到25.1k),它的一个分支PPStructure更是此开源项目的一个亮点,用于解决文档智能(版面分析、版面恢复、表格结构化、信息抽取等)领域的问题。
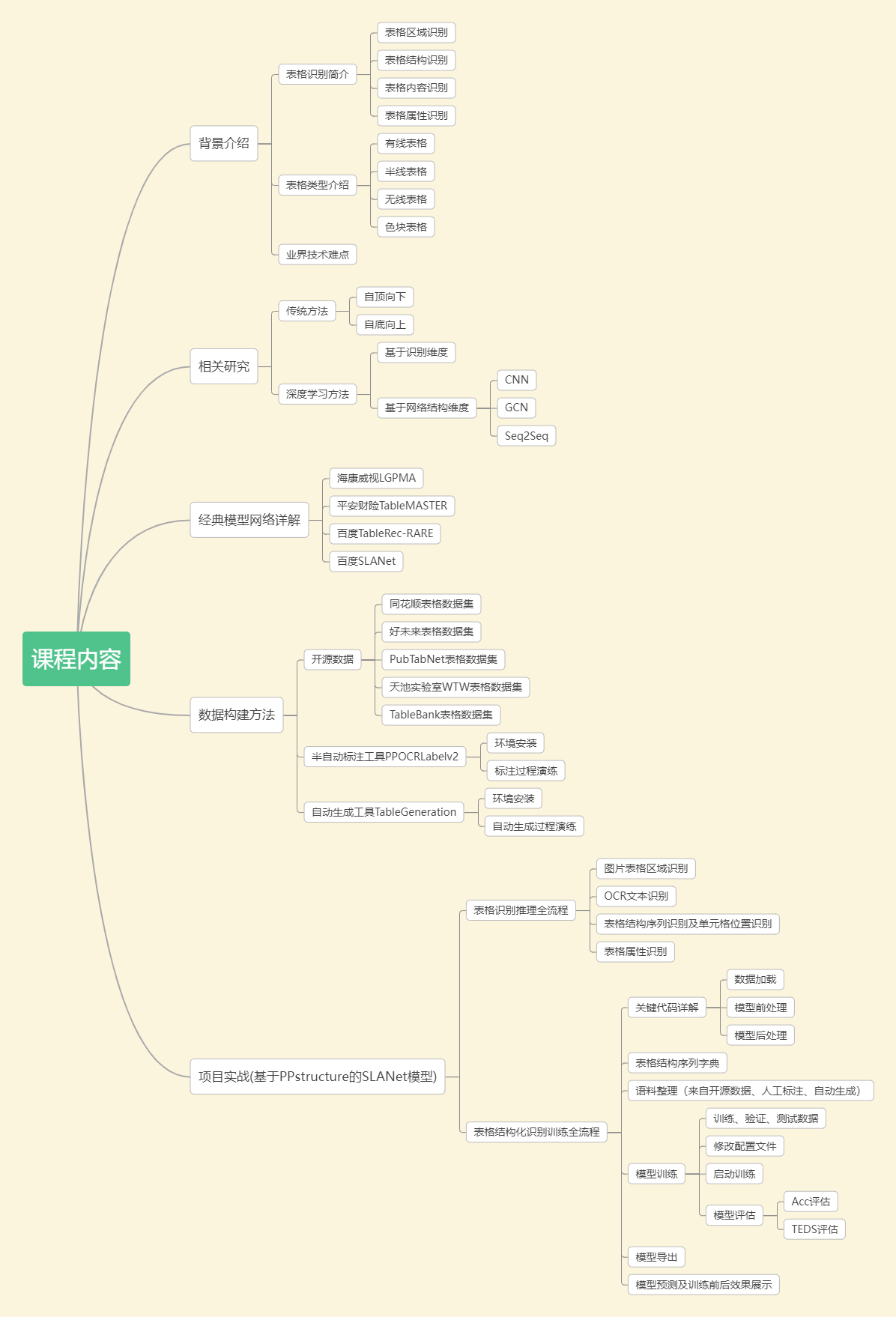
本课程也是在该开源项目基础上,从背景到难点、从传统方法到深度学习、从数据到训练、从模型理论到实战,全面讲解表格结构化识别技术:
1)算法模型:着重讲解LGPMA(海康威视)、TableMASTER(平安财险)、TableRec-RARE(PPstructurev1)、SLANet(PPstructurev2)模型;
2)语料构建:提供开源数据、标注工具(PPOCRLabelv2)、自动生成工具(TableGeneration)三个维度的语料构建方法
3)项目实战:讲解PPstructure表格识别的关键源码,并全流程实现项目环境安装、准备自己的数据集、修改配置文件、模型训练及评估、模型导出环节

 分享
分享