决胜AI-强化学习实战系列视频课程
课时介绍
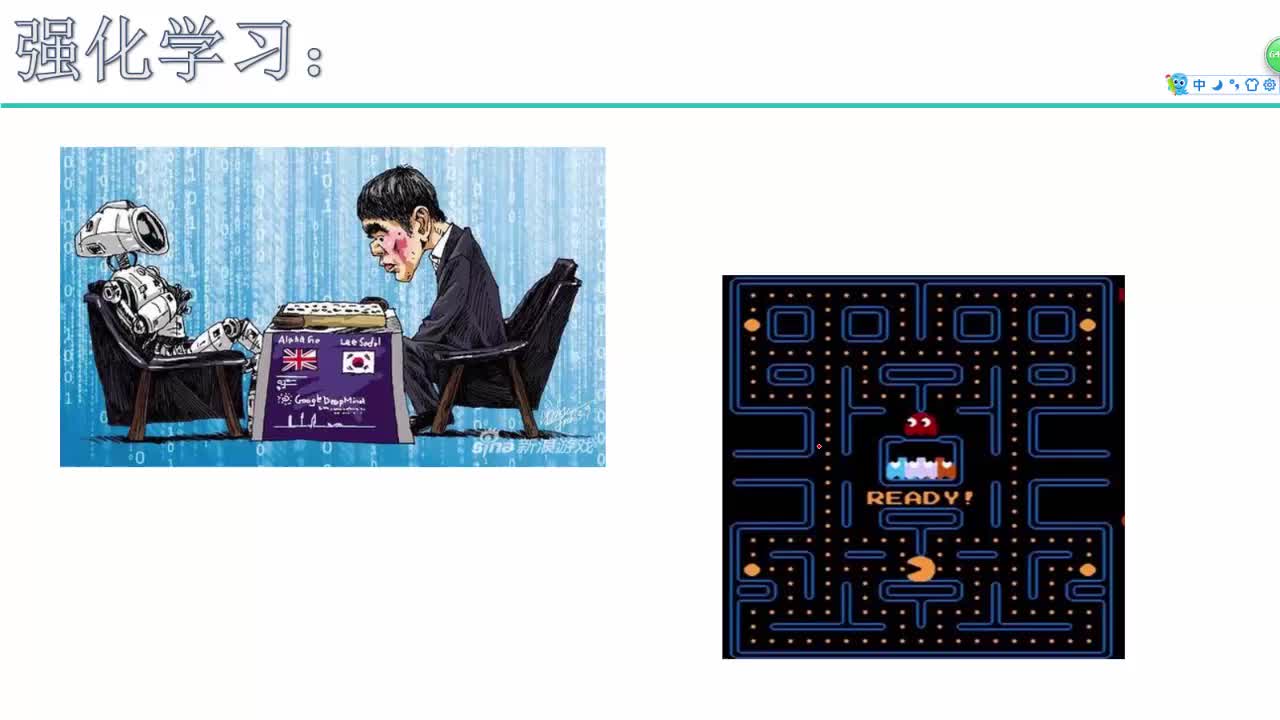
强化学习简介-强化学习基本原理决胜AI-强化学习实战系列视频课程
课程介绍
购买课程后,添加小助手微信(微信号:csdnxy68)回复【唐宇迪】
进入学习群,获取唐宇迪老师答疑
强化学习实战视频培训教程概况:强化学习是当下爆火的机器学习经典模型,系列课程从实例出发,形象解读强化学习如何完整一个实际任务。由基本概念过度到马尔科夫决策过程,通过实例演示如何通过迭代求解来得出来好的决策。举例讲解强化学习(Q-Learning)算法的原理以及如何将强化学习和深度学习进行结合。后通过让AI自动玩游戏的项目实战实例演示如何实现用强化学习和卷积神经网络打造DQN网络模型。
推荐课程

信息系统项目管理师自考笔记
李明 · 393人在学
python从0到1:期货量化交易系统(CTP实战,高频及合成K线数据
王先生 · 17735人在学

手把手搭建Java超市管理系统【附源码】(毕设)
汤小洋 · 3764人在学
Java毕设springboot外卖点餐系统 毕业设计毕设源码 使用教
黄菊华 · 669人在学
基于SSM酒店管理系统(毕设)
小尼老师 · 694人在学
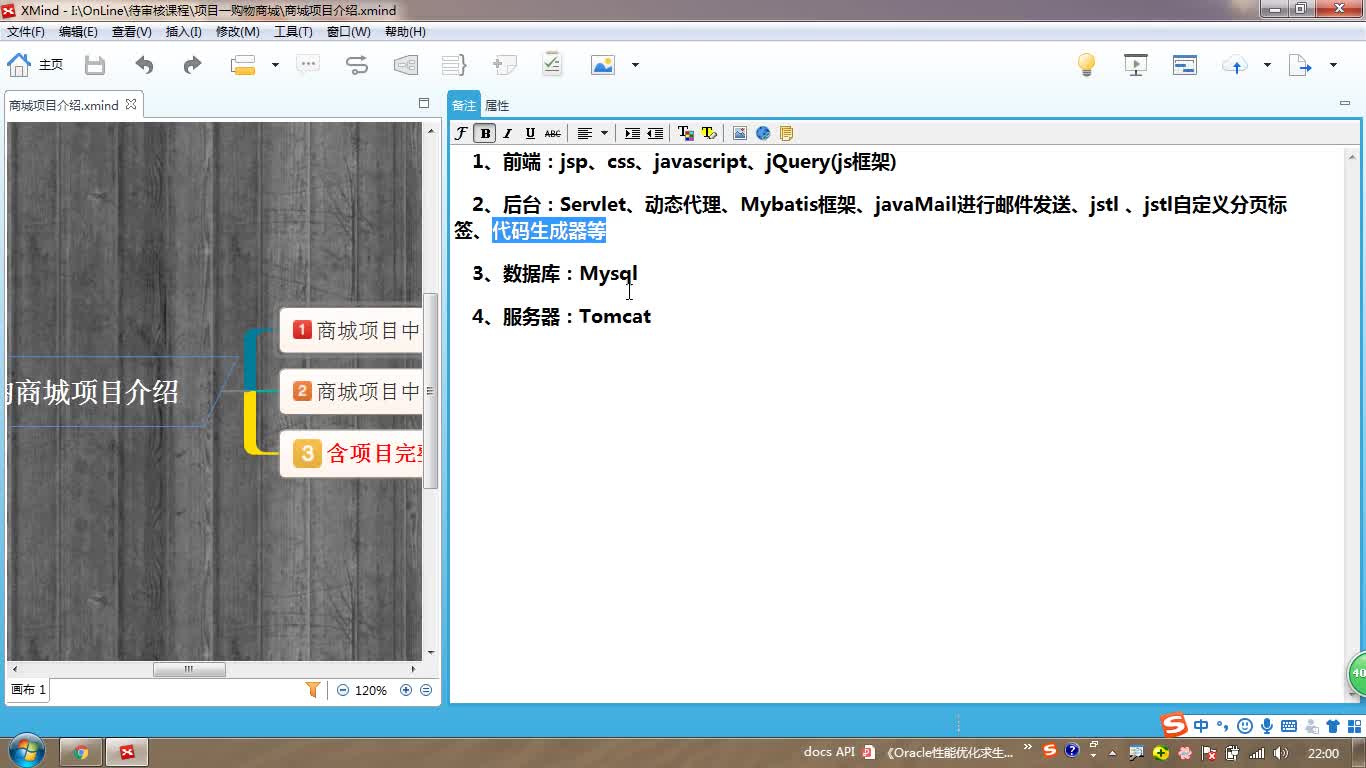
java项目实战之购物商城(java毕业设计)
Long · 4935人在学

手把手搭建Java求职招聘系统【附源码】(毕设)
汤小洋 · 1373人在学
Python Django 深度学习 小程序
钟翔 · 2116人在学

城管局门前三包管理系统+微信小程序(vue+springboot)
赖国荣 · 400人在学
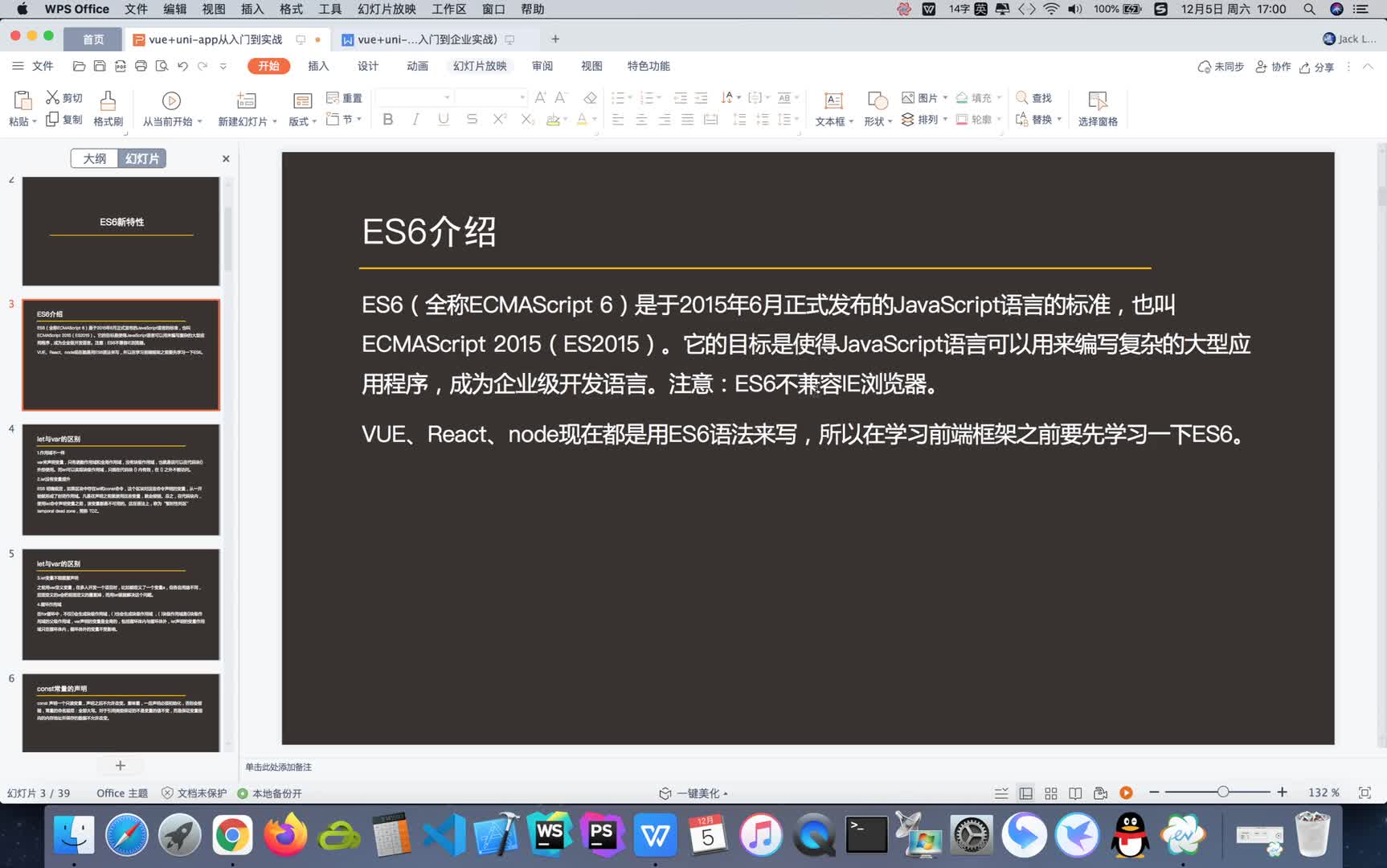
Vue+Uni-app(uniapp)入门与实战+赠送仿美团点餐小程序
李杰 · 3544人在学