从零开始学scrapy网络爬虫

课时介绍
课程介绍
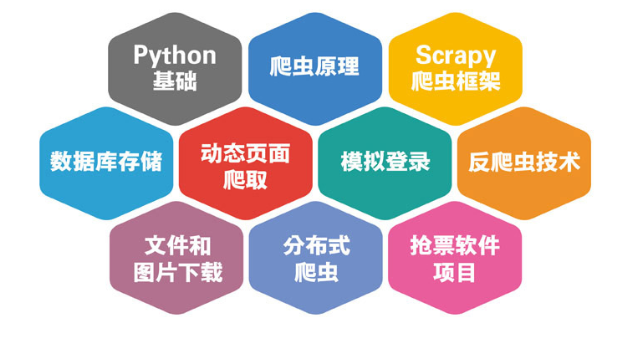
课程目标
《从零开始学Scrapy网络爬虫》从零开始,循序渐进地介绍了目前流行的网络爬虫框架Scrapy。即使你没有任何编程基础,学习起来也不会有压力,因为我们有针对性地介绍了Python编程技术。另外,《从零开始学Scrapy网络爬虫》在讲解过程中以案例为导向,通过对案例的不断迭代、优化,让读者加深对知识的理解,并通过14个项目案例,提高学习者解决实际问题的能力。
适合对象
爬虫初学者、爬虫爱好者、高校相关专业的学生、数据爬虫工程师。
课程介绍
《从零开始学Scrapy网络爬虫》共13章。其中,第1~4章为基础篇,介绍了Python基础、网络爬虫基础、Scrapy框架及基本的爬虫功能。第5~10章为进阶篇,介绍了如何将爬虫数据存储于MySQL、MongoDB和Redis数据库中;如何实现异步AJAX数据的爬取;如何使用Selenium和Splash实现动态网站的爬取;如何实现模拟登录功能;如何突破反爬虫技术,以及如何实现文件和图片的下载。第11~13章为高级篇,介绍了使用Scrapy-Redis实现分布式爬虫;使用Scrapyd和Docker部署分布式爬虫;使用Gerapy管理分布式爬虫,并实现了一个抢票软件的综合项目。
由于目标网站可能会对页面进行改版或者升级反爬虫措施,如果发现视频中的方法无法成功爬取数据,敬请按照页面实际情况修改XPath的路径表达式。视频教程主要提供理论、方法支撑。我们也会在第一时间更新源代码,谢谢!

课程特色


信息系统项目管理师自考笔记
李明 · 393人在学
python从0到1:期货量化交易系统(CTP实战,高频及合成K线数据
王先生 · 17740人在学

手把手搭建Java超市管理系统【附源码】(毕设)
汤小洋 · 3766人在学
Java毕设springboot外卖点餐系统 毕业设计毕设源码 使用教
黄菊华 · 669人在学
基于SSM酒店管理系统(毕设)
小尼老师 · 694人在学
java项目实战之购物商城(java毕业设计)
Long · 4935人在学

手把手搭建Java求职招聘系统【附源码】(毕设)
汤小洋 · 1374人在学
Python Django 深度学习 小程序
钟翔 · 2116人在学

城管局门前三包管理系统+微信小程序(vue+springboot)
赖国荣 · 400人在学
Vue+Uni-app(uniapp)入门与实战+赠送仿美团点餐小程序
李杰 · 3546人在学