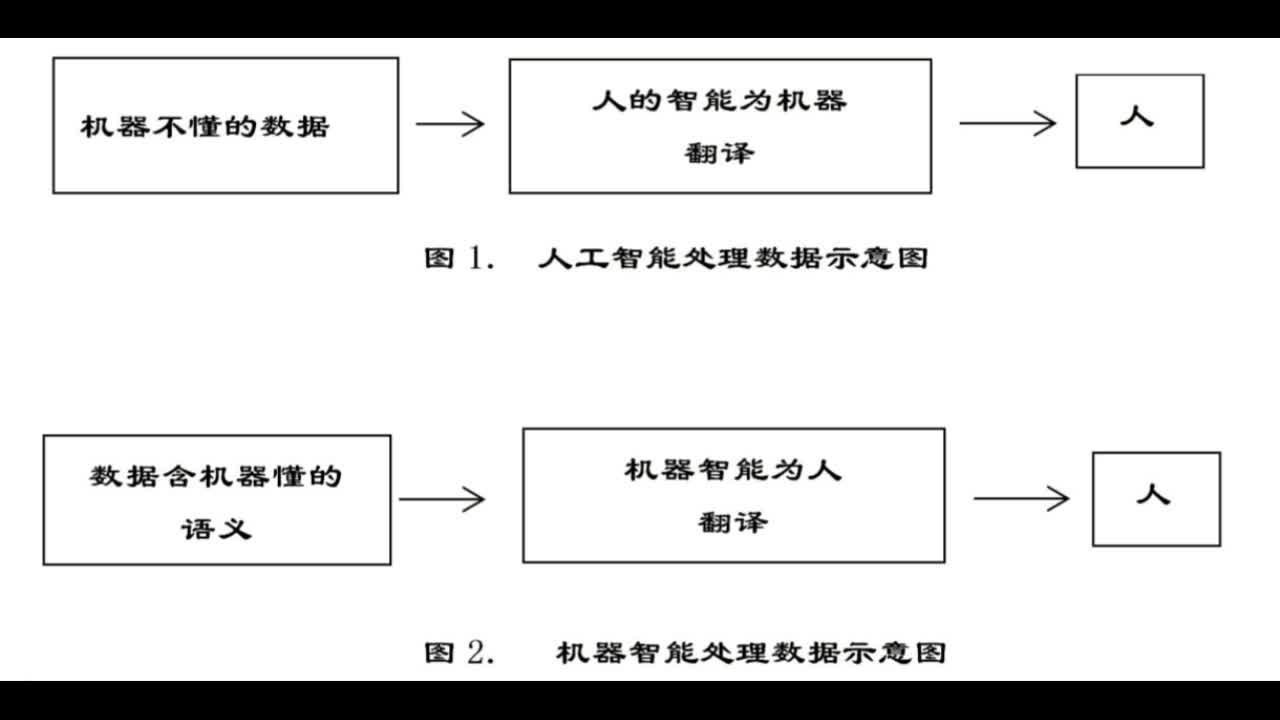
采用实验演示和解说的形式,带您畅游“科学家梦想的互联网”。传统计算机科学理论认为的不能问题,是能实现的。
让科学家梦想的互联网变为现实
无限期 视频有效期
18节 节数
1520人 学习人数
课程评分
 分享
分享 

让科学家梦想的互联网变为现实
科学家梦想的互联网,是互联网之父,伯纳斯.李的梦想,是理想的互联网。
根据传统计算机科学理论,计算机科学家认为:科学家梦想的互联网只不过是一个梦,无法实现。
但是,“让科学家梦想的互联网变为现实---实验演示”却被评选为“发现2017中国互联网驱动新活力“是示范案例。
“科学家梦想的互联网”果真实现了? 这里,就用实验演示回答这个问题,并带您畅游“科学家梦想的互联网”,畅游未来互联网。
复制链接
扫一扫
研究员/技术专家/教授
具有长期在高等学校科研和教学的经历,我国改革开放后首批访美学者。创立了比特标记技术、Ubit语义计算和层次标记编码等理论。解决了一些计算机科学技术的重要问题,理论和实验证明:一些计算机科学家的梦想能够变为现实。
具有长期在高等学校科研和教学的经历,我国改革开放后首批访美学者。创立了比特标记技术、Ubit语义计算和层次标记编码等理论。解决了一些计算机科学技术的重要问题,理论和实验证明:一些计算机科学家的梦想能够变为现实。